
Saturday, December 27, 2014
ITPalooza Kanban and Continuous Delivery presentation
This was definitely a great event to share Kanban and Continuous delivery experiences with other agile practitioners in South Florida. I thank IT Palooza and the South Florida Agile Association for the opportunity.

Friday, December 26, 2014
On security: news without validation - The case of ntpd for MAC OSX
It is a shame that even Hacker News reported as many many others inaccurate information about the recent several NTP vulnerabilties affecting the ntpd daemon in *NIX systems.
Apple computers are not patched automatically if the users do not select to do so, a feature that was added with Yosemite so most likely not even available in many MACs in use out there.
Sysadmins should be encouraged to reach out their user base so the MACs are patched. As a difference with Ubuntu and other linux distros where most likely ntpdate is being used to synchronize time in MACs the ntpd daemon is used. Yes, this is not just a server issue when it comes to MAC OS-X.
BTW back to ntpd vulnerabilities. Follow apple instructions for correct remediation. As explained there 'what /usr/sbin/ntpd' should be run to check the proprietary OSX ntpd version.
What is interesting here is that 'ntpd --version' still returns 4.2.6 after the patch which according to the official ntpd distribution communication does not contain the patch. Version 4.2.8 does.
Apple computers are not patched automatically if the users do not select to do so, a feature that was added with Yosemite so most likely not even available in many MACs in use out there.

Sysadmins should be encouraged to reach out their user base so the MACs are patched. As a difference with Ubuntu and other linux distros where most likely ntpdate is being used to synchronize time in MACs the ntpd daemon is used. Yes, this is not just a server issue when it comes to MAC OS-X.
BTW back to ntpd vulnerabilities. Follow apple instructions for correct remediation. As explained there 'what /usr/sbin/ntpd' should be run to check the proprietary OSX ntpd version.
What is interesting here is that 'ntpd --version' still returns 4.2.6 after the patch which according to the official ntpd distribution communication does not contain the patch. Version 4.2.8 does.
Thursday, December 25, 2014
Do you practice careful and serious reading?
Do you practice careful and serious reading? This is the ultimate question I have come to ask when someone claims to have read the book and clearly I find out s(he) meant to say "eyes went" instead of "mind went" through the content of the book. There is a difference between "becoming familiar" and "digesting" a topic.
When you carefully read a book you take notes. I personally do not like to highlight books as the highlighters I have seen so far as of December 2014 will literally ruin the book. I think taking notes not only help with deep understanding of the content but ultimately it becomes a great summary for further "quick reference".
When you seriously read a book you know what you disagree and agree upon, you are not in a sofa distracted by familiar sounds. You are in a quite space, fully concentrated in receiving a message, processing the message and coming up with your own conclusions, questions and ultimately must importantly answers to the unknown which now suddenly becomes part of your personal wisdom.
It is discouraging to sustain a debate around a book content when there is not careful and serious reading. In my opinion "reading" when it comes to a specific subject matter means "studying" and of course you can only claim you have studied a subject if you have carefully and seriously read the related material. Seeing a book is not the same as looking into a book. Listening to an audio book content is not the same as hearing it.
When you carefully read a book you take notes. I personally do not like to highlight books as the highlighters I have seen so far as of December 2014 will literally ruin the book. I think taking notes not only help with deep understanding of the content but ultimately it becomes a great summary for further "quick reference".
When you seriously read a book you know what you disagree and agree upon, you are not in a sofa distracted by familiar sounds. You are in a quite space, fully concentrated in receiving a message, processing the message and coming up with your own conclusions, questions and ultimately must importantly answers to the unknown which now suddenly becomes part of your personal wisdom.
It is discouraging to sustain a debate around a book content when there is not careful and serious reading. In my opinion "reading" when it comes to a specific subject matter means "studying" and of course you can only claim you have studied a subject if you have carefully and seriously read the related material. Seeing a book is not the same as looking into a book. Listening to an audio book content is not the same as hearing it.
Thursday, December 18, 2014
How to SVN diff local agaist newer revision of item
From command line I would expect that a simple 'svn diff local/path/to/resource' will provide differences between local copy and subversion server copy. However that is not a case as a special '-r HEAD' needs to be added to the command instead. Here is how to add an alias for 'svndiff' so that you can get the differences:
Tuesday, December 16, 2014
NodeJS https to https proxy for transitions to Single Page applications like AngularJS SPA
If you are working on a migration from classical web sites to Single Page Applications (SPA) you will find yourself dealing with a domain where all the code lives, mixed technologies for which you are forced to run the backend server and bunch of inconveniences like applying database migrations or redeploying backend code.
You should be able to develop the SPA locally though and consume the APIs remotely but you probably do not want to allow cross domain requests or even separate the application in two different domains.
A reverse proxy should help you big time. With a reverse proxy you can concentrate on just developing your SPA bits locally while hitting the existing API remotely and yet being able to remotely deploy the app when ready. All you need to do is detect where the SPA is running and route through the local proxy the API requests.
Node http-proxy can be used to create an https-to-https proxy as presented below:
You should be able to develop the SPA locally though and consume the APIs remotely but you probably do not want to allow cross domain requests or even separate the application in two different domains.
A reverse proxy should help you big time. With a reverse proxy you can concentrate on just developing your SPA bits locally while hitting the existing API remotely and yet being able to remotely deploy the app when ready. All you need to do is detect where the SPA is running and route through the local proxy the API requests.
Node http-proxy can be used to create an https-to-https proxy as presented below:
Wednesday, December 10, 2014
Adding ppid to ps aux
The usual way BSD style ps command is used does not return the parent process id (ppid). To add it you need to use the "o" option as follows:
Tuesday, December 09, 2014
Is your bank or favorite online shop insecure? You are entitled to act as a conscious user
UPDATE: A+ should be your target now.
Is your bank of favorite online shop insecure? You are entitled to act as a conscious user. How?
The first thing any company out there should do with their systems is to make sure that traffic between the customer and the service provider is strongly encrypted. All you need to do is to visit this SSL Server Test, insert the URL for the site and expect the results.
If you do not get an A (right now *everybody* is vulnerable to latest Poodle strike so expect to see a B as the best case scenario) you should be concerned. If you get a C or lower please immediately contact the service provider demanding they correct their encryption problems.
Be specially wary of those who have eliminated their websites from SSL Labs. Security *just* by Obscurity does not work!!!
Is your bank of favorite online shop insecure? You are entitled to act as a conscious user. How?
The first thing any company out there should do with their systems is to make sure that traffic between the customer and the service provider is strongly encrypted. All you need to do is to visit this SSL Server Test, insert the URL for the site and expect the results.
If you do not get an A (right now *everybody* is vulnerable to latest Poodle strike so expect to see a B as the best case scenario) you should be concerned. If you get a C or lower please immediately contact the service provider demanding they correct their encryption problems.
Be specially wary of those who have eliminated their websites from SSL Labs. Security *just* by Obscurity does not work!!!
Monday, December 08, 2014
Libreoffice and default Microsoft Excel 1900 Date System
The custom date in format m/d/yy is not formatted in libreoffice but instead a number is shown. This number corresponds to the serial day starting at January, 1 1900. So 5 will correspond to 1905. But there is a leap year bug for which a correction needs to be made (if (serialNumber > 59) serialNumber -= 1) as you can see in action in this runnable.
So if you convert excel to CSV for example and you get a number instead of an expected date, go to that Excel file from the libreoffice GUI and convert a cell to Date to see if the output makes sense as a date. At that point, convinced that those are indeed dates all you need to do is apply the algorithm to the numbers to convert them to dates in the resulting CSV.
So if you convert excel to CSV for example and you get a number instead of an expected date, go to that Excel file from the libreoffice GUI and convert a cell to Date to see if the output makes sense as a date. At that point, convinced that those are indeed dates all you need to do is apply the algorithm to the numbers to convert them to dates in the resulting CSV.
Sunday, December 07, 2014
On Strict-Transport-Security: Protecting your app starts by protecting your users
Protecting your app starts by protecting your users. There are several HTTP headers you should already be using in your web apps but one usually overlooked is Strict-Transport-Security
This header ensures that the browser will refuse to connect if there is a certificate problem like in an invalid certificate presented by a MIM attack coming from a malware in a user's computer. Without this header the user will be giving away absolutely all "secure" traffic to the attacker. Additionally this header will make sure the browser uses only https protocol which means no insecure/unencrypted/plain text communication happens with the server.
The motivation for not using this header could be to allow mixing insecure content in your pages or to allow using self signed certificates in non production servers. I believe such motivation is dangerous when you consider the risk. Your application will be more secure if you address security in the backend and in the front end, the same way you should do validations in the front end and the backend.
This header ensures that the browser will refuse to connect if there is a certificate problem like in an invalid certificate presented by a MIM attack coming from a malware in a user's computer. Without this header the user will be giving away absolutely all "secure" traffic to the attacker. Additionally this header will make sure the browser uses only https protocol which means no insecure/unencrypted/plain text communication happens with the server.
The motivation for not using this header could be to allow mixing insecure content in your pages or to allow using self signed certificates in non production servers. I believe such motivation is dangerous when you consider the risk. Your application will be more secure if you address security in the backend and in the front end, the same way you should do validations in the front end and the backend.
Friday, December 05, 2014
On risk management: Do you practice Continuous Web Application Security?
Do you practice Continuous Web Application Security? Continuously delivering software should include security. Just like with backup-restore tests this is a a very important topic, usually overlooked.
Here is an affordable practical proposal for continuous web application security:
Congratulations. You have just added continuous web application security to your SDLC.
Here is an affordable practical proposal for continuous web application security:
- Have a Ubuntu Desktop (I personally like to see what is going on when it comes to the UI related testing) with your end to end (E2E) platform of choice running on it.
- From your continous integration (CI) of choice hit (remotely) a local runner that triggers your automated E2E test suite against your application URL. I strongly believe that E2E concerns belong to whoever is in charge of developing the UX/UI.
- E2E tests should open your browse of preference and you should be able to *see* what is going on in the browser.
- A proxy based passive scanner like zaproxy should be installed. Below is how to install it from sources:
- If you want to start the proxy with a user interface so you can look into the history of found vulnerabilities through a nice UI and assuming you installed it from the recipe then run it as '/opt/zap/zap.sh' or if you get issues with your display like it happened to me while using xrdp with 'ssh -X localhost /opt/zap/zap.sh'.
-
In order to proxy all requests from chrome we need to follow the below steps.
- From zap proxy menu export the Root CA certificate using "Tools | Options | Dynamic SSL Certificates | Save"
- From Chrome settings search for "certificate", click "Manage Certificates | Authorities | Import | All Files"; select the exported cer file and select "trust his certificate for identifying websites"
- Your E2E runner must be started after you run the below commands because the browser should be started after these commands in order to use the proxy.
export http_proxy=localhost:8080 export https_proxy=localhost:8080
- To stop the proxy and resume E2E without it, we just need to reset the two variables and restart the E2E runner.
LEGACY 12.04: For the proxy to get the traffic from chrome you need to configure the ubuntu system proxy with the commands below. All traffic will now go through the zaproxy. If you want to turn the proxy off just run the first command. To turn it on run just the second but run them all if you are unsure about the current configuration. This is a machine where you just run automated tests so it is expected that you run no browser manually there BTW and that is the reason I forward all the http traffic through the proxy: - Every time your tests run you will be collecting data about possible vulnerabilities
- You could go further now and inspect the zaproxy results via the REST API consuming JSON or XML in your CI pipeline in fact stopping whole deployments from happening. You can take a less radical approach and get the information in plain HTML. Below for example we extract all the alerts in HTML obtained while passively browsing http://google.com. It is assumed that you have run '/opt/zap/zap.sh -daemon' which allows to access from http:/zap base URL the REST API:
- If you want to access this API from outside the box you will need to run '/opt/zap/zap.sh -daemon -host 0.0.0.0 -p 8081' however keep in mind the poor security available for this api.
- Do not forget to restart the proxy after vulnerabilities are fixed or stop and start it automatically before the tests are run so you effectively collect the latest vulnerabilities only
- Your CI might have a plugin for active scanning (See https://wiki.jenkins-ci.org/display/JENKINS/Zapper+Plugin) or not. Starting an active scanning automatically should be easy.
Congratulations. You have just added continuous web application security to your SDLC.
How to parse any valid date format in Talend?
How to parse any valid date format in Talend? This is a question that comes up every so often and the simple answer is that there is not plain simple way that will work for everybody. Valid dates format depend on locale and if you are in the middle of a project supporting multiple countries and languages YMMV.
You will need to use Talend routines. For example you can create a stringToDate() custom method. In its simpler form (considering you are tackling just one locale) you will pass just a String a parameter (not the locale). You will need to add the formats you will allow like you see in the function below. The class and the main method are just for testing purposes and you can see it in action here. These days is so much easier to share snippets of code that actually run ;-)
You will need to use Talend routines. For example you can create a stringToDate() custom method. In its simpler form (considering you are tackling just one locale) you will pass just a String a parameter (not the locale). You will need to add the formats you will allow like you see in the function below. The class and the main method are just for testing purposes and you can see it in action here. These days is so much easier to share snippets of code that actually run ;-)
Wednesday, December 03, 2014
Are your web security scanners good enough?
Are your web security scanners good enough? Note that use plural here as there is no silver bullet. There is no such thing as the perfect security tool.
More than two years ago I posted a self starting guide to get into penetration testing which brought some interest for some talks, consultancy hours and good friends. Not much have been changed until last month when in the Google Security Blog we learned that a new tool called Firing Range was been open sourced. I said to myself "finally we have a test bed for web application security scanners" and then the next question immediately popped up "Are the web security scanners I normally use good enough at detecting these well known vulnerabilities?". I would definitely like to get feedback private or public about tool results. For now I have asked 4 different open sourced tools about the plans to enhance their scanners so they can detect vulnerabilities like the ones Firing Range exposes. My tests so far are telling me that I need to look for other scanners as these 4 do not detect the exposed vulnerabilities. I have posted a comment to the Google post but it has not been authorized so far. I was after responding the main question in this post but then I realized that probably if everyone out there run their tests against their tools (free or paid) we could gather some information about those that are doing a better job as we speak in terms of finding Firing Range vulnerabilities. Here is the list of my questions so far:
More than two years ago I posted a self starting guide to get into penetration testing which brought some interest for some talks, consultancy hours and good friends. Not much have been changed until last month when in the Google Security Blog we learned that a new tool called Firing Range was been open sourced. I said to myself "finally we have a test bed for web application security scanners" and then the next question immediately popped up "Are the web security scanners I normally use good enough at detecting these well known vulnerabilities?". I would definitely like to get feedback private or public about tool results. For now I have asked 4 different open sourced tools about the plans to enhance their scanners so they can detect vulnerabilities like the ones Firing Range exposes. My tests so far are telling me that I need to look for other scanners as these 4 do not detect the exposed vulnerabilities. I have posted a comment to the Google post but it has not been authorized so far. I was after responding the main question in this post but then I realized that probably if everyone out there run their tests against their tools (free or paid) we could gather some information about those that are doing a better job as we speak in terms of finding Firing Range vulnerabilities. Here is the list of my questions so far:
- Can anybody share results (bad or good) about web application scanners running against Firing Range?
- Can anybody share other test bed softwares (similar to Firing Range) they are currently using, perhaps a cool honey pot for other to further test scanners?
- Skipfish: https://code.google.com/p/skipfish/issues/detail?id=209
- Nikto: I is a Web Server Scanner and not a Web Application Scanner https://github.com/sullo/nikto/issues/191
- w3af: https://github.com/andresriancho/w3af/issues/6451
- ZAP: https://code.google.com/p/zaproxy/issues/detail?id=1422
Wednesday, November 26, 2014
Error level or priority for Linux syslog
If you grep your linux server logs from time to time you might be surprised at the lack of an error level. If you want to know for example all error logs currently in syslog, how would you go around it? Simple answer you cannot without changing the log format in /etc/syslog.conf.
Let us say you configured to see the priority (%syslogpriority%) as the first character in the log file:
Here is how to force an alert from the cron facility for testing purposes:
Let us say you configured to see the priority (%syslogpriority%) as the first character in the log file:
$ vi /etc/rsyslog.conf ... # # Use traditional timestamp format. # To enable high precision timestamps, comment out the following line. # $template custom,"%syslogpriority%,%syslogfacility%,%timegenerated%,%HOSTNAME%,%syslogtag%,%msg%\n" $ActionFileDefaultTemplate custom ... $ sudo service rsyslog restartTo filter information look at the description of priorities. From http://www.rsyslog.com/doc/queues.html:
Numerical Severity
Code
0 Emergency: system is unusable
1 Alert: action must be taken immediately
2 Critical: critical conditions
3 Error: error conditions
4 Warning: warning conditions
5 Notice: normal but significant condition
6 Informational: informational messages
7 Debug: debug-level messages
A simple grep helps us now:
$ grep '^[0-3]' /var/log/syslog ... 3,3,Nov 26 11:56:15,myserver,monit[17496]:, 'myserver' mem usage of 96.3% matches resource limit [mem usage>80.0%] ...A more readable format:
$ vi /etc/rsyslog.conf ... # # Use traditional timestamp format. # To enable high precision timestamps, comment out the following line. # $template TraditionalFormatWithPRI,"%pri-text%: %timegenerated% %HOSTNAME% %syslogtag%%msg:::drop-last-lf%\n" $ActionFileDefaultTemplate TraditionalFormatWithPRI ... $ sudo service rsyslog restartWould allow you to search as well:
$ grep -E '\.error|\.err|\.crit|\.alert|\.emerg|\.panic' /var/log/syslog ... daemon.err<27>: Nov 26 13:10:18 myserver monit[17496]: 'myserver' mem usage of 95.9% matches resource limit [mem usage>80.0%]From http://www.rsyslog.com/doc/rsyslog_conf_filter.html valid values are debug, info, notice, warning, warn (same as warning), err, error (same as err), crit, alert, emerg, panic (same as emerg).
Here is how to force an alert from the cron facility for testing purposes:
logger -p "cron.alert" "This is a test alert that should be identified by logMonitor"You will get:
cron.alert<73>: Aug 27 08:42:14 sftp krfsadmin: This is a test alert that should be identified by logMOnitorWhich you could inspect with logMonitor.
Monday, November 24, 2014
Being an Effective Manager means being an Effective Coach
Being an Effective Manager means being an Effective Coach. A coach needs to know very well each client. They will all be different, they will have different objectives, they will be able to achieve different goals. However all of clients must be willing to be trained and coached. The coach bases his individual plan on the client existing and needed skills, the ability to perform based on personal goals and the personal will of the individual to succeed. The relationship is bidirectional though, if the will is poor on any side, and/or the ability does not match expected goals, and/or if the skills does not match expected level then the client and the coach are not a good fit for each other.
Management is not any different. Each person is valuable one way or another but nobody is a good match for all type of jobs. The will is necessary, no brainer. As team member is expected to be driven by a will to contribute to the culture, value and profit of the whole group. Skill and Ability are a different story.
The difference between skill and ability is very subtle. I tend to think that a team member has an ability problem when all the manager resources to improve the skills of such "direct" have been tried without success. Of course the development of skills and ability of the "direct" will be affected by the skills and ability of the manager. So then how can we be effective managers?
To be effective managers we need to know each of our directs. They are all different and so in order to set them all for the biggest possible success we need to work in a personalized way with them. I think Managers have a lot to learn from the Montessori school. This is a daily task, if you are or want to be a manager you have to love teaching and caring for others successes.
Management is not any different. Each person is valuable one way or another but nobody is a good match for all type of jobs. The will is necessary, no brainer. As team member is expected to be driven by a will to contribute to the culture, value and profit of the whole group. Skill and Ability are a different story.
The difference between skill and ability is very subtle. I tend to think that a team member has an ability problem when all the manager resources to improve the skills of such "direct" have been tried without success. Of course the development of skills and ability of the "direct" will be affected by the skills and ability of the manager. So then how can we be effective managers?
To be effective managers we need to know each of our directs. They are all different and so in order to set them all for the biggest possible success we need to work in a personalized way with them. I think Managers have a lot to learn from the Montessori school. This is a daily task, if you are or want to be a manager you have to love teaching and caring for others successes.
Java NoSuchAlgorithmException - SunJSSE, sun.security.ssl.SSLContextImpl$DefaultSSLContext
This is one of those misleading issues coming from a log trace which does not tell you the real cause. Most likely if you scroll up in the log file you will find something like:
Caused by: java.security.NoSuchAlgorithmException: Error constructing implementation (algorithm: Default, provider: SunJSSE, class: ... Caused by: java.security.PrivilegedActionException: java.io.FileNotFoundException: /opt/tomcat/certs/customcert.p12 (No such file or directory) ...As a general rule restart the jvm and pay attention to absolutely all errors ;-)
Wednesday, November 19, 2014
Wednesday, November 12, 2014
javax.script.ScriptException: sun.org.mozilla.javascript.EvaluatorException: Encountered code generation error while compiling script: generated bytecode for method exceeds 64K limit
We got this error after upgrading libreoffice as it replaced the symlink "/usr/bin/java -> /etc/alternatives/java" which was still java 6. This issue was corrected in Java 7 so replacing the symlink with the hotspot jdk7 or up should resolve the problem.
Tuesday, November 11, 2014
Libreoffice hanging in headless mode unless using root user
A simple 'libreoffice --headless --help' hanging? Be sure ~/.config exists and its content is owned by the current user:
mkdir -p ~/.config chown -R `logname`:`logname` ~/.configThe above did not work in Ubuntu 12.04 which runs version 3.5. However you can install in 12.04 the same version run in 14.04:
sudo add-apt-repository -y ppa:libreoffice/libreoffice-4-2 && sudo apt-get update && sudo apt-get install libreoffice && libreoffice --versionIn our case there were zillions of these processes stuck in the background BTW so we had to kill them manually:
pkill libreoffice pkill oosplash pkill soffice.bin
Monday, November 03, 2014
The path '.' appears to be part of a Subversion 1.7 or greater
Subversion asking for an upgrade for example after command 'svn status -u' ?
svn: The path '.' appears to be part of a Subversion 1.7 or greater working copy. Please upgrade your Subversion client to use this working copy.
Friday, October 31, 2014
Thread safe concurrent svn update
Subversion (svn) update is not thread safe which means you cannot script an update that could interfere with some other update process or otherwise you will face:
svn: Working copy '.' locked svn: run 'svn cleanup' to remove locks (type 'svn help cleanup' for details)
Thursday, October 30, 2014
Kanban as a driver for continuous delivery
Our Kanban journey so far has been a rewarding experience. You can check my presentation on Continuous delivery to learn why and vote for yet another presentation on the subject in the upcoming 2014 ITPalooza event. The more likes I get the better chances I have to win a spot for the presentation.
Tuesday, October 28, 2014
On security: Avoid weak SSL v3
SSL v3 is a weak protocol we all use without noticing when we access anything “secure” on the web including native applications in our phones.
Applications providers should remove support for it and users/help desk personnel should update browsers. Failure to do this will add to chances to get any of your online accounts compromised.
What steps should you follow to protect yourself?
Applications providers should remove support for it and users/help desk personnel should update browsers. Failure to do this will add to chances to get any of your online accounts compromised.
What steps should you follow to protect yourself?
- Go to https://dev.ssllabs.com/ssltest/viewMyClient.html to understand if your browser is secure
- If you get a message like "Your user agent is vulnerable. You should disable SSL 3.” then follow the instructions from https://zmap.io/sslv3/browsers.html
Monday, October 27, 2014
On security: Test if your site is still using weak SHA1 from command line
Security wise you should check if your website is still using the weak SHA1 algorithm to sign your domain certificate. Marketing wise as well. With Chrome being one of the major web browsers in use out there your users will feel insecure very soon in your website unless you sign your certificate with the sha256 hash algorithm.
Google has announced Chrome will start warning users who try to visit websites that still use sha1 signature algorithm to generate their SSL certificates.
You can of course use https://www.ssllabs.com/ssltest/analyze.html?d=$domain to test those sites available to the wild. For intranet though you need a different tool which happens to work of course also for external sites:
Google has announced Chrome will start warning users who try to visit websites that still use sha1 signature algorithm to generate their SSL certificates.
You can of course use https://www.ssllabs.com/ssltest/analyze.html?d=$domain to test those sites available to the wild. For intranet though you need a different tool which happens to work of course also for external sites:
Saturday, October 25, 2014
Wednesday, October 22, 2014
On security Automate sftp when public key authentication is not available
The real question is why public key authentication is not available. Storing passwords and maintaining them secure is a difficult task specially when those are supposed to be used from automated code.
For some reason you still find servers and clients (which we do not control) that accept only passwords for authentication. My advice is educate but in many cases you simply are out of business if you do not "comply". Interesting ...
If you must connect using password then the below should help. Suppose you have a batch file with sftp commands for example a simple dir command (and others). You can send those to the lftp command: Use this at your own risk. Do not use it before communicating the risks.
For some reason you still find servers and clients (which we do not control) that accept only passwords for authentication. My advice is educate but in many cases you simply are out of business if you do not "comply". Interesting ...
If you must connect using password then the below should help. Suppose you have a batch file with sftp commands for example a simple dir command (and others). You can send those to the lftp command: Use this at your own risk. Do not use it before communicating the risks.
Wednesday, October 08, 2014
svn: E175013: Access to '/some/dir' forbidden
The below error would look like lack of permissions however permissions hadn't change neither the user desktop environment where credentials were saved:
svn: E175013: Access to '/some/dir' forbiddenLooking inside "auth/svn.simple/*" I found a password that I tried but did not work. Password was incorrect and the easiest way to correct the situation is to force to connect with the user again, password will be prompted and after supplying it the svn.simple/* file will get updated:
svn --username myuser mkdir http......
Monday, October 06, 2014
Thursday, September 25, 2014
Thursday, September 11, 2014
Microphone not working in Windows 7 guest running on Virtualbox (v4.3.16) from a MAC OS X (Mavericks) host?
Microphone not working in Windows 7 guest running on Virtualbox (v4.3.16) from a MAC OS X (Mavericks) host?
The very first thing you should do is to change the Audio Controller in VirtualBox. Below is a setting that worked for me:
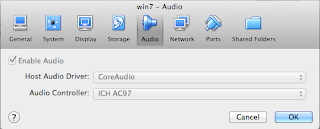
Windows will complain about not finding a suitable audio driver but if you know that all you need is to install a "Realtek AC'97 Driver" for "Windows 7" then you will find http://www.ac97audiodriver.com
After installing the driver followed by a Windows restart you should be able to setup the microphone using the "configure/setup microphone wizard" options. If you get into troubles make sure "properties/advanced" show as default format "2 channels, 16 bit, 44100 Hz (cd quality)" as shown below:
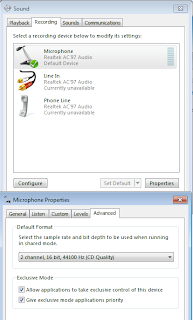
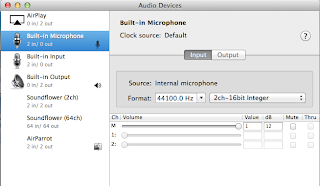
I have read on the web the suggestion that this setting should match the host settings which you can set from the "Audio MIDI Setup" application. I have tried different combinations and it still works, the important thing is to rerun the setup microphone wizard to make sure distortion is kept to a minimum. In any case I left mine with the below settings:
The very first thing you should do is to change the Audio Controller in VirtualBox. Below is a setting that worked for me:

Windows will complain about not finding a suitable audio driver but if you know that all you need is to install a "Realtek AC'97 Driver" for "Windows 7" then you will find http://www.ac97audiodriver.com
After installing the driver followed by a Windows restart you should be able to setup the microphone using the "configure/setup microphone wizard" options. If you get into troubles make sure "properties/advanced" show as default format "2 channels, 16 bit, 44100 Hz (cd quality)" as shown below:

I have read on the web the suggestion that this setting should match the host settings which you can set from the "Audio MIDI Setup" application. I have tried different combinations and it still works, the important thing is to rerun the setup microphone wizard to make sure distortion is kept to a minimum. In any case I left mine with the below settings:

Wednesday, September 10, 2014
Is your team continuously improving? Would you share your Agile / Lean Journey? Bring the JIT to the Software Industry
Is your team continuously improving? Would you share your Agile / Lean Journey?. I hope that my presentation on Continuous delivery will invite others to help bringing to the Software Industry the Just In Time mentality.
Thursday, August 28, 2014
Can we apply the 80-20 rule to find out the Minimal Marketable Feature?
Cam we apply the 80-20 rule ( "for many events, roughly 80% of the effects come from 20% of the causes" ) to find out the Minimal Marketable Feature (MMF)?
In my personal experience over bloated requirements as the norm. So I have the practice (even in my personal life) to analyze the root cause of problems to try to resolve as much as I can with the minimum possible effort. The 80-20 rule becomes my target and unless someone before me actually applied it I can say that in most cases at least I can present an option. Whether that is accepted or not depends on many other factors which I rather not discuss here.
Why this rule is useful in Software development is a well known subject. But making the whole team aware of it comes in handy when there is clear determination to be occupied 100% of the tine in producing value. If we can cut down to 20% the apparently needed requirements our productivity would literally skyrocket. Of course the earlier you do this analysis the better but be prepared because perhaps you, the software engineer will teach a lesson to everybody above when you demonstrate that what was asked is way more than what is needed to resolve the real need of the stakeholder.
In my personal experience over bloated requirements as the norm. So I have the practice (even in my personal life) to analyze the root cause of problems to try to resolve as much as I can with the minimum possible effort. The 80-20 rule becomes my target and unless someone before me actually applied it I can say that in most cases at least I can present an option. Whether that is accepted or not depends on many other factors which I rather not discuss here.
Why this rule is useful in Software development is a well known subject. But making the whole team aware of it comes in handy when there is clear determination to be occupied 100% of the tine in producing value. If we can cut down to 20% the apparently needed requirements our productivity would literally skyrocket. Of course the earlier you do this analysis the better but be prepared because perhaps you, the software engineer will teach a lesson to everybody above when you demonstrate that what was asked is way more than what is needed to resolve the real need of the stakeholder.
Monday, August 25, 2014
We are hiring an experienced Javascript developer who has worked on angularjs for a while
If you have built directives to the point of having configurable widgets using AngularJS and you are interested in working in an agile lean environment where people come first please apply here.
Saturday, August 23, 2014
How to eliminate the waste associated to prioritization and estimation activities?
How to eliminate the waste associated to prioritization and estimation activities?
- 5 minutes per participant meeting: Business stakeholders periodically (depending on how often there are slots available from the IT team) sit to discuss a list of features they need. This list must be short and to ensure that it is stakeholders come with just one feature per participant (if the number of slots is bigger than the number of participants then adjust the number of features by participant). Each feature must be presented with the numeric impact for business ( expected return in terms of hours saved, dollars saved, dollars earned, client acquisition and retention, etc ) and a concrete acceptance criteria ( a feature must be testable and the resulting quality must be measurable ). Each participant is entitled to use 5 minutes maximum to present his/her feature. Not all participants will make a presentation. Sometimes the very first participant shows a big saving idea that nobody else can compete with and the meeting is finalized immediately. That is the idea which should be passed to the IT team.
- The IT team does a Business Analysis, an eliciting of requirements. The responsible IT person (let us call that person Business Analyst or BA) divides the idea implementation in the smallest possible pieces that will provide value after an isolated deployment, no bells and whistles. In other words divide in Minimal Marketable Features (MMF)
- The BA shares with the IT development team the top idea and the breakdown.
- IT engineers READ the proposal and tag each piece with 1 of a limited number of selections from the Fibonacci sequence representing the time in hours (0 1 2 3 5 8 13 21 34 55 89). Hopefully there is nothing beyond 21 and ideally everything should be less than 8 hours (an MMF per day!!!)
- BA informs Business and gets approval for the MMFs. Note how business can now discard some bells and whistles when they realize few MMFs will provide the same ROI. Ideally the BA actively pushes to discard functionality that is expensive without actually bringing back a substantial gain.
- Developers deliver the MMFs and create new slots for the cycle to start all over again.
Wednesday, August 20, 2014
This is a Summary of my posts related to Agile and Lean Project Management
This is a Summary of my posts related to Agile and Lean Project Management which I will try to maintain down the road. I hope it will allow me to share with others who try everyday to lead their teams on the difficult path to achieve a constant pace, predictable and high quality delivery.
http://thinkinginsoftware.blogspot.com/2014/11/being-effective-manager-means-being.html
http://thinkinginsoftware.blogspot.com/2014/10/kanban-as-driver-for-continuous-delivery.html
http://thinkinginsoftware.blogspot.com/2014/08/can-we-apply-80-20-rule-to-find-out.html
http://thinkinginsoftware.blogspot.com/2014/08/how-to-eliminate-waste-associated-to.html
http://thinkinginsoftware.blogspot.com/2014/08/define-pm-in-three-words-predictable.html
http://thinkinginsoftware.blogspot.com/2014/08/speaking-about-software-productivity.html
http://thinkinginsoftware.blogspot.com/2014/08/does-project-management-provides.html
http://thinkinginsoftware.blogspot.com/2014/06/on-productivity-what-versus-how-defines.html
http://thinkinginsoftware.blogspot.com/2014/06/continuous-delivery-must-not-affect.html
http://thinkinginsoftware.blogspot.com/2014/05/continuous-delivery-needs-faster-server.html
http://thinkinginsoftware.blogspot.com/2014/05/is-tdd-dead.html
http://thinkinginsoftware.blogspot.com/2014/04/small-and-medium-tests-should-never.html
http://thinkinginsoftware.blogspot.com/2014/04/continuous-integration-ci-makes.html
http://thinkinginsoftware.blogspot.com/2014/04/agile-interdependence-as-software.html
http://thinkinginsoftware.blogspot.com/2014/04/have-product-vision-before-blaming-it.html
http://thinkinginsoftware.blogspot.com/2014/04/non-functional-requirements-should-be.html
http://thinkinginsoftware.blogspot.com/2014/04/on-agile-minimum-marketable-feature-mmf.html
http://thinkinginsoftware.blogspot.com/2014/04/personal-wip-limit-directly-impacts.html
http://thinkinginsoftware.blogspot.com/2014/04/having-exploratory-meeting-ask-how-will.html
http://thinkinginsoftware.blogspot.com/2014/04/test-coverage-is-secondary-to-defect.html
http://thinkinginsoftware.blogspot.com/2014/04/continuous-improvement-for-people.html
http://thinkinginsoftware.blogspot.com/2014/04/are-you-developing-product-or.html
http://thinkinginsoftware.blogspot.com/2014/04/got-continuous-product-delivery-then.html
http://thinkinginsoftware.blogspot.com/2014/04/lean-is-clean-without-c-for-complexity.html
http://thinkinginsoftware.blogspot.com/2014/03/on-lean-thinking-continuous-delivery.html
http://thinkinginsoftware.blogspot.com/2014/02/wip-limit-versus-batch-size-fair.html
http://thinkinginsoftware.blogspot.com/2014/01/is-kanban-used-as-buzz-word.html
http://thinkinginsoftware.blogspot.com/2014/01/kanban-wip-limit-how-to.html
http://thinkinginsoftware.blogspot.com/2013/12/kanban-prioritization-estimation.html
http://thinkinginsoftware.blogspot.com/2013/11/kanban-show-stale-issues-to-reach.html
http://thinkinginsoftware.blogspot.com/2013/07/agile-team-did-you-already-script-your.html
http://thinkinginsoftware.blogspot.com/2013/04/it-agile-and-lean-hiring.html
http://thinkinginsoftware.blogspot.com/2013/02/the-car-factory-software-shop-and-la.html
http://thinkinginsoftware.blogspot.com/2014/11/being-effective-manager-means-being.html
http://thinkinginsoftware.blogspot.com/2014/10/kanban-as-driver-for-continuous-delivery.html
http://thinkinginsoftware.blogspot.com/2014/08/can-we-apply-80-20-rule-to-find-out.html
http://thinkinginsoftware.blogspot.com/2014/08/how-to-eliminate-waste-associated-to.html
http://thinkinginsoftware.blogspot.com/2014/08/define-pm-in-three-words-predictable.html
http://thinkinginsoftware.blogspot.com/2014/08/speaking-about-software-productivity.html
http://thinkinginsoftware.blogspot.com/2014/08/does-project-management-provides.html
http://thinkinginsoftware.blogspot.com/2014/06/on-productivity-what-versus-how-defines.html
http://thinkinginsoftware.blogspot.com/2014/06/continuous-delivery-must-not-affect.html
http://thinkinginsoftware.blogspot.com/2014/05/continuous-delivery-needs-faster-server.html
http://thinkinginsoftware.blogspot.com/2014/05/is-tdd-dead.html
http://thinkinginsoftware.blogspot.com/2014/04/small-and-medium-tests-should-never.html
http://thinkinginsoftware.blogspot.com/2014/04/continuous-integration-ci-makes.html
http://thinkinginsoftware.blogspot.com/2014/04/agile-interdependence-as-software.html
http://thinkinginsoftware.blogspot.com/2014/04/have-product-vision-before-blaming-it.html
http://thinkinginsoftware.blogspot.com/2014/04/non-functional-requirements-should-be.html
http://thinkinginsoftware.blogspot.com/2014/04/on-agile-minimum-marketable-feature-mmf.html
http://thinkinginsoftware.blogspot.com/2014/04/personal-wip-limit-directly-impacts.html
http://thinkinginsoftware.blogspot.com/2014/04/having-exploratory-meeting-ask-how-will.html
http://thinkinginsoftware.blogspot.com/2014/04/test-coverage-is-secondary-to-defect.html
http://thinkinginsoftware.blogspot.com/2014/04/continuous-improvement-for-people.html
http://thinkinginsoftware.blogspot.com/2014/04/are-you-developing-product-or.html
http://thinkinginsoftware.blogspot.com/2014/04/got-continuous-product-delivery-then.html
http://thinkinginsoftware.blogspot.com/2014/04/lean-is-clean-without-c-for-complexity.html
http://thinkinginsoftware.blogspot.com/2014/03/on-lean-thinking-continuous-delivery.html
http://thinkinginsoftware.blogspot.com/2014/02/wip-limit-versus-batch-size-fair.html
http://thinkinginsoftware.blogspot.com/2014/01/is-kanban-used-as-buzz-word.html
http://thinkinginsoftware.blogspot.com/2014/01/kanban-wip-limit-how-to.html
http://thinkinginsoftware.blogspot.com/2013/12/kanban-prioritization-estimation.html
http://thinkinginsoftware.blogspot.com/2013/11/kanban-show-stale-issues-to-reach.html
http://thinkinginsoftware.blogspot.com/2013/07/agile-team-did-you-already-script-your.html
http://thinkinginsoftware.blogspot.com/2013/04/it-agile-and-lean-hiring.html
http://thinkinginsoftware.blogspot.com/2013/02/the-car-factory-software-shop-and-la.html
Solaris calculating date difference
It is common necessity to know how long our script takes. In Solaris 11 just as any linux system the below will work:
However in Solaris 10 and below it won't and so a hack will be needed.
Monday, August 18, 2014
Define PM in three words: Predictable Quality Delivery
Define PM in three words: Predictable Quality Delivery.
I can't help to look at PM from the Product Management angle rather than from the Project Management angle. The three constraints (scope, schedule and cost) might be great for building the first version of a product but enhancement, maintenance, the future is a different story. Without a constant pace delivery it will be difficult to remain competitive. That constant pace cannot be supported if quality is not the number one concern in your production lane.
In order to provide value, PM should ensure the team has "hight quality predictable delivery".
I can't help to look at PM from the Product Management angle rather than from the Project Management angle. The three constraints (scope, schedule and cost) might be great for building the first version of a product but enhancement, maintenance, the future is a different story. Without a constant pace delivery it will be difficult to remain competitive. That constant pace cannot be supported if quality is not the number one concern in your production lane.
In order to provide value, PM should ensure the team has "hight quality predictable delivery".
Sunday, August 17, 2014
Speaking about software productivity, does your team write effective code?
Speaking about software productivity, does your team write effective code?
Most people think about efficiency when it comes to productivity. This is only logical as most people think tactically in order to resolve specific problems. These are our "problem solvers". However as a reminder Productivity is not just about Efficiency but firstly about Effectiveness. Thinking strategically *as well* will bring to the team the maximum level of productivity. These, effective programmers are "solutions providers" What can we do to be effective programmers?
Dr. Axel Rauschmayer in his book Speaking Javascript, Chapter 26 explains, IMO, what the effective software development team should do. This applies to any programming language BTW. This is what I take from his statements. This is what I support based on my own experience as a programmer:
Most people think about efficiency when it comes to productivity. This is only logical as most people think tactically in order to resolve specific problems. These are our "problem solvers". However as a reminder Productivity is not just about Efficiency but firstly about Effectiveness. Thinking strategically *as well* will bring to the team the maximum level of productivity. These, effective programmers are "solutions providers" What can we do to be effective programmers?
Dr. Axel Rauschmayer in his book Speaking Javascript, Chapter 26 explains, IMO, what the effective software development team should do. This applies to any programming language BTW. This is what I take from his statements. This is what I support based on my own experience as a programmer:
- Define your code style and follow it. Be consistent.
- Use descriptive and meaningful identifiers: "redBalloon is easier to read than rdBlln"
- Break up long functions/methods into smaller ones. This will make the code *almost* self documented
- Use comments only to complement the code meaning to explain the *why* and not the how
- Use documentation only to complement the comments meaning provide the big picture, how to get started and a glossary of probably unknown terms
- Write the simplest possible code which means code for a sustainable future. In the words of Brian Kernighan "Everyone knows that debugging is twice as hard as writing a program in the first place. So if you are as clever as you can be when you write it, how will you ever debug it?"
Thursday, August 14, 2014
Tuesday, August 12, 2014
Install telnet in Solaris 11
Why would you do this? Make sure you communicate the security risk involved to those who asked you to enable it. Here it goes anyway:
Friday, August 01, 2014
Does Project Management provide Business Value?
Does Project Management provide Business Value? A similar question came up in LinkedIn and I decided to share my ideas on it.
Project Management is part of any product lifecycle. It is a discipline that should help a team achieve a specific goal. It is needed either as a responsibility of a dedicated individual/department or the whole team.
A team should achieve "predictable delivery with high quality" and for that to happen you will need to measure several productivity KPI. In the words of Joseph E. Stiglitz “What you measure affects what you do,” and “If you don’t measure the right thing, you don’t do the right thing.”.
So IMO if the PM discipline adjust to these ideas PM discipline is to be considered 'an integral part of the overall success of the team'. If these ideas are still not introduced in your team then the PM discipline is a 'must-do' to get you to new levels of productivity. If the PM discipline is thought to be in place but not adjusting to these ideas I would definitely consider it an 'overhead'.
Project Management is part of any product lifecycle. It is a discipline that should help a team achieve a specific goal. It is needed either as a responsibility of a dedicated individual/department or the whole team.
A team should achieve "predictable delivery with high quality" and for that to happen you will need to measure several productivity KPI. In the words of Joseph E. Stiglitz “What you measure affects what you do,” and “If you don’t measure the right thing, you don’t do the right thing.”.
So IMO if the PM discipline adjust to these ideas PM discipline is to be considered 'an integral part of the overall success of the team'. If these ideas are still not introduced in your team then the PM discipline is a 'must-do' to get you to new levels of productivity. If the PM discipline is thought to be in place but not adjusting to these ideas I would definitely consider it an 'overhead'.
Wednesday, July 09, 2014
Solaris remote public key authorization
Still a pain in Solaris 11. Openssh ssh-copy-id still does not work as expected so the process is manual unless you want to risk having multiple keys authorized for the same host remotely.
Thursday, July 03, 2014
On SMTP: RCPT To: command verb versus to: header
Ever wondered why you got an email with "to:" being some other address and not yours? Perhaps you got an email stating "to: Undisclosed recipients:;", why? you might have asked.
To simplify the explanation here the RCPT command using the verb “to:” is used to direct the email to a specific address. In the last mile the email will be received by the addressee but only the "to:" header if present will be accessible. If it is missing you get "to: Undisclosed recipients:;" and if it is set you get whatever it says. Clearly you can use a different email address there which will generate in some cases a heck of confusion ;-). You can confirm this yourself just by using telnet as usual for SMTP:
To simplify the explanation here the RCPT command using the verb “to:” is used to direct the email to a specific address. In the last mile the email will be received by the addressee but only the "to:" header if present will be accessible. If it is missing you get "to: Undisclosed recipients:;" and if it is set you get whatever it says. Clearly you can use a different email address there which will generate in some cases a heck of confusion ;-). You can confirm this yourself just by using telnet as usual for SMTP:
Tuesday, July 01, 2014
Variable syntax: cshell is picky. Use braces to refer to variables
If cshell (csh) is your default shell after you login ~/.cshrc will be parsed. If you get the error "variable syntax" your next step if to figure out what shell config file is declaring a variable incorrectly. The below is correct:
Just remove the braces and you will end up with the "variable syntax" error.
Friday, June 27, 2014
Solaris pkgutil is not idempotent
Life would be easier if command line tools would never use exit code different than zero unless as a 'real' error pops up. The fact that I am trying to install again an existing package should not result in an 'error' but Solaris returns status 4 when running 'pkg install' with description "No updates necessary for this image.". You have no other option than handling this in a per package basis like I show below using a Plain Old Bash (POB) recipe:
Devops need no words but code: How to forward all Solaris user emails to an external email account
Devops need no words but code.
Monday, June 23, 2014
Talend tFileExcelInput uses jexcelapi which is deprecated instead of favoring Apache POI
Talend tFileExcelInput uses jexcelapi which is deprecated instead of favoring Apache POI Talend. The alternative seems to be using one of the tFileExcel* components from Talend Exchange or converting Excel to CSV from command line and then processing that file format later on.
Thursday, June 19, 2014
The most efficient way to send emails from Ubuntu shell script or cron
What is the most efficient way to send an email from Ubuntu shell script or cron? I have found sendEmail wins the battle:
sudo apt-get install sendemail echo $CONTENT_BODY | \ sendEmail -f $FROM -t $TO1 $TO2 \ -s $MAIL_SERVER_HOSTNAME -u $SUBJECT > /dev/nullHere is an example of its usage from cron BTW.
How difficult is to report JIRA Worklog?
How difficult is to report JIRA Worklog? There are several plugins and a couple of API call for free but none of them so far can report on a basic metric: How many hours each member of the team worked per ticket in a particular date or date range.
I do not like to go to the database directly but rather I prefer API endpoints, however while I wait for a free solution to this problem I guess the most effective way to pull such information is unfortunately to query the jira database directly.
Below is an example to get the hours per team member and ticket for yesterday. You could tweak this example to get all kind of information about worklog. If you want to include custom fields like 'Team' see below:
I do not like to go to the database directly but rather I prefer API endpoints, however while I wait for a free solution to this problem I guess the most effective way to pull such information is unfortunately to query the jira database directly.
Below is an example to get the hours per team member and ticket for yesterday. You could tweak this example to get all kind of information about worklog. If you want to include custom fields like 'Team' see below:
Tuesday, June 17, 2014
Saturday, June 14, 2014
On Productivity: What versus How defines Effectiveness versus Efficiency, Strategy versus Tactics and Leader versus Manager
What versus How defines Effectiveness versus Efficiency, Strategy versus Tactics, Leader versus Manager. They are not to be confused. The first is the "crawl", the second is the "walk" and without them both you will never "run". Following baby steps works for business as well as for nature.
What do you produce? Is it what the customers need or what you think they should need? Being effective means to do *what* is required, no more, no less. You have to Have a solid strategy to be effective. Being effective will ultimately make you a leader because you will influence and inspire.
How do you produce it? Are you focused on predictable delivery with high quality or on resource utilization? Being efficient means to focus on "how" to do the whole job on time and on budget. Being efficient means to create tactics that align completely with the strategy. Being efficient will ultimately make you a manager because you will be able to direct and control.
Mastering these concepts is crucial to be able to become the head of any personal or professional effort but arguably desired to be a member of an all stars team. Defining "what" to do (the goal, the mission, the end), is step number one. Determining "how" it will get done (the effort, the actions, the means) is the second step.
Productivity is the ratio between the production of "what" we do versus the cost associated to "how" we do it. It is a result of how effective and efficient we are. It is the ultimately head's and arguably, again, every team member performance review. You need no review performed by a supervisor to know where you stand as a contributor. Have a strategy and constantly monitor that your tactics align with it. Let us strive to *effectively lead what is agreed and efficiently manage how it is delivered*.
What do you produce? Is it what the customers need or what you think they should need? Being effective means to do *what* is required, no more, no less. You have to Have a solid strategy to be effective. Being effective will ultimately make you a leader because you will influence and inspire.
How do you produce it? Are you focused on predictable delivery with high quality or on resource utilization? Being efficient means to focus on "how" to do the whole job on time and on budget. Being efficient means to create tactics that align completely with the strategy. Being efficient will ultimately make you a manager because you will be able to direct and control.
Mastering these concepts is crucial to be able to become the head of any personal or professional effort but arguably desired to be a member of an all stars team. Defining "what" to do (the goal, the mission, the end), is step number one. Determining "how" it will get done (the effort, the actions, the means) is the second step.
Productivity is the ratio between the production of "what" we do versus the cost associated to "how" we do it. It is a result of how effective and efficient we are. It is the ultimately head's and arguably, again, every team member performance review. You need no review performed by a supervisor to know where you stand as a contributor. Have a strategy and constantly monitor that your tactics align with it. Let us strive to *effectively lead what is agreed and efficiently manage how it is delivered*.
Friday, June 13, 2014
Is Java slow for web development? Code, compile, deploy is a necessary evil, but not for development
Is Java slow for web development? Code, compile, deploy is a necessary evil, but not for development. We want just to change and test.
Even those that decide to go with interpreted languages at some point need to compile and deploy for scalability purposes. This is not rocket science. As an oversimplified explanation, if the runtime application code needs to be interpreted every time it runs then resources are used inefficiently.
When Java Servlet specification appeared in the market at the end of the 90's we were already coding web dynamic pages using CGI (C and even unsafe unix power tools), Perl and PHP. We were developing fast indeed, Why did we move towards Java? There is no simple answer but for one Java scaled to way more concurrent users.
And yet we were coding Model 1 at the beginning. That meant we could put the code in the infamous JSP scriptlets and see the results immediately in the browser just as PHP did.
Then several papers convinced us that separation of concerns were needed and we moved to Model 2 where the application logic was now in compiled servlets and the presentation code was in JSP. At that point the JVM should have had what it didn't have for years: Dynamic Code reloading.
In the early 00's Sun shipped JDK 1.4 with Hotswap to address the issue, but only partially. Only changes in methods would be dynamically reloaded so if you change anything from a simple method name to a new class you will need to recompile and redeploy.
In 2000 though JUnit hit the market and many Java developers have relied on tools like automated compilation and test run from CLI or IDE. This technique has allowed us to rapidly develop functionality while providing automated test cases. Of course when the time comes to test in the application server fast code replacement is a must have. The pain continues when not only dynamic languages like python and ruby are more developer friendly but on top of them new frameworks appear offering rapid code generation.
At the end of 2007 jrebel hit the market. Since its inception it has been free for Open Source Projects but Commercial for the enterprise. Clearly still an issue for small companies like startups where you want to save every penny.
In the early 10's Sun engaged in a research partnership called Dynamic Code Evolution VM (DCEVM) which has been recently forked and actively maintained so far.
Concentrated on the efficiencies of the runtime the JVM has not evolved as we all would have expected. Instead the JVM has become the foundation to run more dynamic languages like ruby and scala for example.
Many people have moved to languages like Groovy, others have moved to use frameworks like Play but the common denominator has been the lack of an effective Hotswap engine.
Enough of history. It is 2014 and here is how you patch the latest version of jdk 1.7 ( Once we conclude our java 8 migration I will be posting instructions in this blog ) to allow in place class reloading. In addition I am including how to deploy HotSwapAgent for your typical MVC java application. HotswapAgent supports Spring, Hibernate and more. I have tested this with jdk1.7.0_6 (jdk-7u60-linux-x64.tar.gz):
Even those that decide to go with interpreted languages at some point need to compile and deploy for scalability purposes. This is not rocket science. As an oversimplified explanation, if the runtime application code needs to be interpreted every time it runs then resources are used inefficiently.
When Java Servlet specification appeared in the market at the end of the 90's we were already coding web dynamic pages using CGI (C and even unsafe unix power tools), Perl and PHP. We were developing fast indeed, Why did we move towards Java? There is no simple answer but for one Java scaled to way more concurrent users.
And yet we were coding Model 1 at the beginning. That meant we could put the code in the infamous JSP scriptlets and see the results immediately in the browser just as PHP did.
Then several papers convinced us that separation of concerns were needed and we moved to Model 2 where the application logic was now in compiled servlets and the presentation code was in JSP. At that point the JVM should have had what it didn't have for years: Dynamic Code reloading.
In the early 00's Sun shipped JDK 1.4 with Hotswap to address the issue, but only partially. Only changes in methods would be dynamically reloaded so if you change anything from a simple method name to a new class you will need to recompile and redeploy.
In 2000 though JUnit hit the market and many Java developers have relied on tools like automated compilation and test run from CLI or IDE. This technique has allowed us to rapidly develop functionality while providing automated test cases. Of course when the time comes to test in the application server fast code replacement is a must have. The pain continues when not only dynamic languages like python and ruby are more developer friendly but on top of them new frameworks appear offering rapid code generation.
At the end of 2007 jrebel hit the market. Since its inception it has been free for Open Source Projects but Commercial for the enterprise. Clearly still an issue for small companies like startups where you want to save every penny.
In the early 10's Sun engaged in a research partnership called Dynamic Code Evolution VM (DCEVM) which has been recently forked and actively maintained so far.
Concentrated on the efficiencies of the runtime the JVM has not evolved as we all would have expected. Instead the JVM has become the foundation to run more dynamic languages like ruby and scala for example.
Many people have moved to languages like Groovy, others have moved to use frameworks like Play but the common denominator has been the lack of an effective Hotswap engine.
Enough of history. It is 2014 and here is how you patch the latest version of jdk 1.7 ( Once we conclude our java 8 migration I will be posting instructions in this blog ) to allow in place class reloading. In addition I am including how to deploy HotSwapAgent for your typical MVC java application. HotswapAgent supports Spring, Hibernate and more. I have tested this with jdk1.7.0_6 (jdk-7u60-linux-x64.tar.gz):
From tomcat to resin for development purposes
Tomcat reloads the application context when a change is detected in a class file in WEB-INF/classes directory. Resin reloads just the class out of the box which is more efficient. When combined with Dynamic Code Evolution VM (DCEVM) and HotSwapAgent you could cut on development time as the changes could include more serious refactoring like renaming methods.
Here is how I tested in resin an application previously running in tomcat which uses Spring, JPA and Hibernate.
Download resin open source version from http://caucho.com/products/resin/download/gpl#download
If you use log4j in your application then replace catalina.home for the full local path in log4j.properties (if you use log4j) for example:
If you are using special libraries loaded from the server container then copy them to resin lib directory:
Here is how I tested in resin an application previously running in tomcat which uses Spring, JPA and Hibernate.
Download resin open source version from http://caucho.com/products/resin/download/gpl#download
If you use log4j in your application then replace catalina.home for the full local path in log4j.properties (if you use log4j) for example:
log4j.appender.logfile.File=/var/log/resin/app.log
instead of:
log4j.appender.logfile.File=${catalina.home}/logs/app.log
Configure resin to load external resources like app.properties. In /etc/resin/resin.xml:
Add special JVM flags as needed in resin.xml:
If you are using special libraries loaded from the server container then copy them to resin lib directory:
cp -r /opt/tomcat/lib/jtds-1.2.4.jar /usr/local/share/resin-4.0.40/lib/ cp -r /opt/tomcat/lib/mysql-connector-java-5.1.26-bin.jar /usr/local/share/resin-4.0.40/lib/ cp -r /opt/tomcat/lib/tomcat-jdbc.jar /usr/local/share/resin-4.0.40/lib/ cp -r /opt/tomcat/bin/tomcat-juli.jar /usr/local/share/resin-4.0.40/lib/Restart resin and look into the logs: Check changes to any class are efficiently reloaded (just the class changed should be reloaded). For example copying from maven target directory:
cp /path/to/workspace/app/target/classes/com/sample/web/OfficeController.class /var/resin/webapps/app/WEB-INF/classes/com/sample/web/Resin is less permissive in terms of schema validations. Tomcat would allow "xsi:schemaLocation" in taglib tag to be all lowwer case. You can either correct taglibs or use the below in WEB-INF/resin-web.xml: If you have any problems testing resin look for answers or post your question in the resin forum.
Wednesday, June 11, 2014
Find java code in use and/or unused
Install ucdetector for Eclipse. I would love to have a command line tool to address the same, probably subject for another research. For today I was able to undersatnd how many SOAP requests were actually used from the current code.
Jenkins Artifactory plugin - SLF4J: Class path contains multiple SLF4J bindings
We found this issue after migrating our jenkins and artifactory servers:
===[JENKINS REMOTING CAPACITY]===channel started SLF4J: Class path contains multiple SLF4J bindings. SLF4J: Found binding in [jar:file:/home/krfsadmin/.jenkins/cache/artifactory-plugin/2.2.2/slf4j-jdk14-1.6.2.jar!/org/slf4j/impl/StaticLoggerBinder.class] SLF4J: Found binding in [jar:file:/home/krfsadmin/.jenkins/cache/jars/3E/F61A988E582517AA842B98FA54C586.jar!/org/slf4j/impl/StaticLoggerBinder.class] SLF4J: See http://www.slf4j.org/codes.html#multiple_bindings for an explanation. Failed to instantiate SLF4J LoggerFactory Reported exception: java.lang.NoClassDefFoundError: org/slf4j/spi/LoggerFactoryBinder at java.lang.ClassLoader.defineClass1(Native Method) at java.lang.ClassLoader.defineClass(ClassLoader.java:792) at java.security.SecureClassLoader.defineClass(SecureClassLoader.java:142) at java.net.URLClassLoader.defineClass(URLClassLoader.java:449) at java.net.URLClassLoader.access$100(URLClassLoader.java:71) at java.net.URLClassLoader$1.run(URLClassLoader.java:361) at java.net.URLClassLoader$1.run(URLClassLoader.java:355) at java.security.AccessController.doPrivileged(Native Method) at java.net.URLClassLoader.findClass(URLClassLoader.java:354) at org.codehaus.plexus.classworlds.realm.ClassRealm.loadClassFromSelf(ClassRealm.java:386) at org.codehaus.plexus.classworlds.strategy.SelfFirstStrategy.loadClass(SelfFirstStrategy.java:42) at org.codehaus.plexus.classworlds.realm.ClassRealm.loadClass(ClassRealm.java:244) at org.codehaus.plexus.classworlds.realm.ClassRealm.loadClass(ClassRealm.java:230) at org.codehaus.plexus.classworlds.realm.ClassRealm.loadClassFromParent(ClassRealm.java:405) at org.codehaus.plexus.classworlds.strategy.SelfFirstStrategy.loadClass(SelfFirstStrategy.java:46) at org.codehaus.plexus.classworlds.realm.ClassRealm.loadClass(ClassRealm.java:244) at java.lang.ClassLoader.loadClass(ClassLoader.java:411) at java.lang.ClassLoader.loadClass(ClassLoader.java:357) at org.slf4j.LoggerFactory.bind(LoggerFactory.java:129) at org.slf4j.LoggerFactory.performInitialization(LoggerFactory.java:108) at org.slf4j.LoggerFactory.getILoggerFactory(LoggerFactory.java:302) at org.slf4j.LoggerFactory.getLogger(LoggerFactory.java:276) at org.slf4j.LoggerFactory.getLogger(LoggerFactory.java:288) at hudson.maven.Maven3Builder$MavenExecutionListener.Not sure if the cache directory was copied over but the bottom line is that the duplication of jar files can be eliminated of course when as we eliminate any duplication:(Maven3Builder.java:352) at hudson.maven.Maven3Builder.call(Maven3Builder.java:114) at hudson.maven.Maven3Builder.call(Maven3Builder.java:69) at hudson.remoting.UserRequest.perform(UserRequest.java:118) at hudson.remoting.UserRequest.perform(UserRequest.java:48) at hudson.remoting.Request$2.run(Request.java:328) at hudson.remoting.InterceptingExecutorService$1.call(InterceptingExecutorService.java:72) at java.util.concurrent.FutureTask$Sync.innerRun(FutureTask.java:334) at java.util.concurrent.FutureTask.run(FutureTask.java:166) at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1145) at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:615) at java.lang.Thread.run(Thread.java:724) Caused by: java.lang.ClassNotFoundException: org.slf4j.spi.LoggerFactoryBinder at org.codehaus.plexus.classworlds.strategy.SelfFirstStrategy.loadClass(SelfFirstStrategy.java:50) at org.codehaus.plexus.classworlds.realm.ClassRealm.loadClass(ClassRealm.java:244) at org.codehaus.plexus.classworlds.realm.ClassRealm.loadClass(ClassRealm.java:230) ... 35 more channel stopped ERROR: Failed to parse POMs java.io.IOException: Remote call on Channel to Maven [/opt/jdk/bin/java, -Dfile.encoding=UTF-8, -Dm3plugin.lib=/opt/jenkins/plugins/artifactory/WEB-INF/lib, -cp, /home/krfsadmin/.jenkins/plugins/maven-plugin/WEB-INF/lib/maven3-agent-1.5.jar:/opt/maven/boot/plexus-classworlds-2.x.jar, org.jvnet.hudson.maven3.agent.Maven3Main, /opt/maven, /opt/apache-tomcat-7.0.52/webapps/jenkins/WEB-INF/lib/remoting-2.41.jar, /home/krfsadmin/.jenkins/plugins/maven-plugin/WEB-INF/lib/maven3-interceptor-1.5.jar, /home/krfsadmin/.jenkins/plugins/maven-plugin/WEB-INF/lib/maven3-interceptor-commons-1.5.jar, 44464] failed at hudson.remoting.Channel.call(Channel.java:748) at hudson.maven.ProcessCache$MavenProcess.call(ProcessCache.java:160) at hudson.maven.MavenModuleSetBuild$MavenModuleSetBuildExecution.doRun(MavenModuleSetBuild.java:843) at hudson.model.AbstractBuild$AbstractBuildExecution.run(AbstractBuild.java:518) at hudson.model.Run.execute(Run.java:1706) at hudson.maven.MavenModuleSetBuild.run(MavenModuleSetBuild.java:529) at hudson.model.ResourceController.execute(ResourceController.java:88) at hudson.model.Executor.run(Executor.java:231) Caused by: java.lang.NoClassDefFoundError: org/slf4j/spi/LoggerFactoryBinder at java.lang.ClassLoader.defineClass1(Native Method) at java.lang.ClassLoader.defineClass(ClassLoader.java:792) at java.security.SecureClassLoader.defineClass(SecureClassLoader.java:142) at java.net.URLClassLoader.defineClass(URLClassLoader.java:449) at java.net.URLClassLoader.access$100(URLClassLoader.java:71) at java.net.URLClassLoader$1.run(URLClassLoader.java:361) at java.net.URLClassLoader$1.run(URLClassLoader.java:355) at java.security.AccessController.doPrivileged(Native Method) at java.net.URLClassLoader.findClass(URLClassLoader.java:354) at org.codehaus.plexus.classworlds.realm.ClassRealm.loadClassFromSelf(ClassRealm.java:386) at org.codehaus.plexus.classworlds.strategy.SelfFirstStrategy.loadClass(SelfFirstStrategy.java:42) at org.codehaus.plexus.classworlds.realm.ClassRealm.loadClass(ClassRealm.java:244) at org.codehaus.plexus.classworlds.realm.ClassRealm.loadClass(ClassRealm.java:230) at org.codehaus.plexus.classworlds.realm.ClassRealm.loadClassFromParent(ClassRealm.java:405) at org.codehaus.plexus.classworlds.strategy.SelfFirstStrategy.loadClass(SelfFirstStrategy.java:46) at org.codehaus.plexus.classworlds.realm.ClassRealm.loadClass(ClassRealm.java:244) at java.lang.ClassLoader.loadClass(ClassLoader.java:411) at java.lang.ClassLoader.loadClass(ClassLoader.java:357) at org.slf4j.LoggerFactory.bind(LoggerFactory.java:129) at org.slf4j.LoggerFactory.performInitialization(LoggerFactory.java:108) at org.slf4j.LoggerFactory.getILoggerFactory(LoggerFactory.java:302) at org.slf4j.LoggerFactory.getLogger(LoggerFactory.java:276) at org.slf4j.LoggerFactory.getLogger(LoggerFactory.java:288) at hudson.maven.Maven3Builder$MavenExecutionListener. (Maven3Builder.java:352) at hudson.maven.Maven3Builder.call(Maven3Builder.java:114) at hudson.maven.Maven3Builder.call(Maven3Builder.java:69) at hudson.remoting.UserRequest.perform(UserRequest.java:118) at hudson.remoting.UserRequest.perform(UserRequest.java:48) at hudson.remoting.Request$2.run(Request.java:328) at hudson.remoting.InterceptingExecutorService$1.call(InterceptingExecutorService.java:72) at java.util.concurrent.FutureTask$Sync.innerRun(FutureTask.java:334) at java.util.concurrent.FutureTask.run(FutureTask.java:166) at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1145) at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:615) at java.lang.Thread.run(Thread.java:724) Caused by: java.lang.ClassNotFoundException: org.slf4j.spi.LoggerFactoryBinder at org.codehaus.plexus.classworlds.strategy.SelfFirstStrategy.loadClass(SelfFirstStrategy.java:50) at org.codehaus.plexus.classworlds.realm.ClassRealm.loadClass(ClassRealm.java:244) at org.codehaus.plexus.classworlds.realm.ClassRealm.loadClass(ClassRealm.java:230) ... 35 more [ci-game] evaluating rule: Build result
mv ~/.jenkins/cache/artifactory-plugin/2.2.2/slf4j-jdk14-1.6.2.jar ~/
Sunday, June 08, 2014
Is a report any different than other application Views?
Is a report any different than other application Views? I don't think so. Your architecture should have several View/Renderer Engines and Controller/Processor Engines. When would you call "Report" any given View?
The Latin word "reportare" means "carry back". When we build reports as Software Engineers all we do is accept some parameters or a simple request and bring back a response with a specific format in a specific media. As it happens when we deliver a paper after a phone call in Software we deliver a pdf/excel/word file or embedded view in a native application or a website. It can be just plane or formatted text in a native application, a simple HTML fragment for a web application or website, and the list goes on.
But what is the difference between this "response" and any other application response? Is it that a report is created with a WYSIWYG application where datasets and a specific Domain Specific Language (SDL) is used? Is it that they take longer to be produced than a regular view?
IMO deciding what is a report and what is not is certainly difficult in some cases. For example if you ask a Microsoft Engineer for a report out of certain transformations that are necessary, the solution will include some SSIS and SSRS projects. Here you use two tools which hopefully you can combine behind a user interface and make it transparent to the user.
Any software application we build will have some kind of user interaction and a response to that user interaction (Even if some Views result from automated tasks and are sent as email attachments, they still have at a minimum some hardcoded setup and most likely some configuration to read before executing). I sustain that a report is not any different than any other application View. It needs a renderer engine and a processor engine. The combination of processors and renderers can result in the most complicated logic being executed and *reported* back to the user. The application *reports* constantly to the user.
Use any tool that makes sense to build your application Views. Call some of them "report" if you want. But at the end of the row you need View/Renderer Engines and Controller/Processor Engines available to "carry back" to application users the response they are expecting. The combination of these two engines give you the power to deliver an application structure that meets any demand without having to argue if what you are building is actually a "report". If you are carrying back information to the user you are reporting to the user.
ETL and Report tools are just that, tools. The architecture should not name components based on the tools being used.
The Latin word "reportare" means "carry back". When we build reports as Software Engineers all we do is accept some parameters or a simple request and bring back a response with a specific format in a specific media. As it happens when we deliver a paper after a phone call in Software we deliver a pdf/excel/word file or embedded view in a native application or a website. It can be just plane or formatted text in a native application, a simple HTML fragment for a web application or website, and the list goes on.
But what is the difference between this "response" and any other application response? Is it that a report is created with a WYSIWYG application where datasets and a specific Domain Specific Language (SDL) is used? Is it that they take longer to be produced than a regular view?
IMO deciding what is a report and what is not is certainly difficult in some cases. For example if you ask a Microsoft Engineer for a report out of certain transformations that are necessary, the solution will include some SSIS and SSRS projects. Here you use two tools which hopefully you can combine behind a user interface and make it transparent to the user.
Any software application we build will have some kind of user interaction and a response to that user interaction (Even if some Views result from automated tasks and are sent as email attachments, they still have at a minimum some hardcoded setup and most likely some configuration to read before executing). I sustain that a report is not any different than any other application View. It needs a renderer engine and a processor engine. The combination of processors and renderers can result in the most complicated logic being executed and *reported* back to the user. The application *reports* constantly to the user.
Use any tool that makes sense to build your application Views. Call some of them "report" if you want. But at the end of the row you need View/Renderer Engines and Controller/Processor Engines available to "carry back" to application users the response they are expecting. The combination of these two engines give you the power to deliver an application structure that meets any demand without having to argue if what you are building is actually a "report". If you are carrying back information to the user you are reporting to the user.
ETL and Report tools are just that, tools. The architecture should not name components based on the tools being used.
Saturday, June 07, 2014
javax.mail.MessagingException: Could not convert socket to TLS
This error happened after we migrated Jenkins to a bigger server. The configurations were alike and the mail server configured was internal. Apparently there were no mail changes so why the error I don't have a clue. I ended up authorizing the domain.
Friday, June 06, 2014
Continuous delivery must not affect user experience
Continuous delivery must not affect user experience. What to do then to support restarting a JEE application? Think about the Front End. Have a rich web front end tier and present the user a message like you have seen before in sites like Gmail:

The above is of course related to the lack of connection but you can easily inform the user that you are retrying for other issues as well. See below a different message Gmail sends back to the user when for example I change my /etc/hosts to point mail.google.com to yahoo.com ;-)

This creates the opportunity to restart the server and catch any 5XX HTTP Errors, then retry until the backend server is back. Needless to say it is expected that your backend server comes back sooner than later.

The above is of course related to the lack of connection but you can easily inform the user that you are retrying for other issues as well. See below a different message Gmail sends back to the user when for example I change my /etc/hosts to point mail.google.com to yahoo.com ;-)

This creates the opportunity to restart the server and catch any 5XX HTTP Errors, then retry until the backend server is back. Needless to say it is expected that your backend server comes back sooner than later.
Thursday, June 05, 2014
Uninstall couchdb in Ubuntu
Couchdb ships with an uninstall make option so the below steps should cover you. I had installed version 1.2.0 so here we go:
Saturday, May 31, 2014
Continuous delivery needs faster server startup. Could #Tomcat #Spring applications cope with that?
I am reluctant to accept th emyth that Java web applications don't fit well in agile environments. The main criticism is the fact that unless you use a commercial tool, a plugin architecture or an OSGI modularized app you will end up having to restart the server in order to deploy the latest application version.
But what about if actually the time that the application would take to load would be few seconds? Will a user differentiate 10 seconds delay originated from a slow database access or backend channel web service request in comparison with a server restart? The answer is: No, the user experiencing a delay does not really care about the nature of it. If we maintain a proper SLA this will be simply "a hiccup".
Even the fastest web services out there would be slow for certain random actions. You will never know if Gmail is taking longer because of a quick server restart for example. As long as you can get what you need a wait of few seconds won't natter.
If the definition of "Done" is "Deployed to production" developers will take more care of deployment performance. Waiting long time for a deployment, means disruption. Business will never approve minutes of downterm. On the other hand if you increase your WIP limits you will slow down, quality will suffer. This bottleneck becomes a great opportunity for improvement as expected. You have reach a Kaisen moment.
There is a need to work on deplopyment performence. Without addressing that important issue you will constantly delay deployments, you will constantly get more tasks piling up, the consequences will be terrible and will only be discovered if you are actually visualizing the value stream. You need to tune your server and your application for it to load faster. A restart should be a synonym of a snap.
In a typical Spring application you will proceed as with any other application. Logs are your friends. Go ahead and turn on debug level. Search for "initialization completed" and confirm how much time this process takes. In production you better use lazy initialization:
It should become evident from simple log inspection what is the culprit for a slow server startup. Let us review the below example:

The first clear issue is that ”Initializing Spring root WebApplicationContext” takes 36 seconds which is almost half of the time the whole server takes to startup. The second issue is that “Initializing Spring FrameworkServlet” takes 14 seconds which is a moderate 10% of the whole server startup time. Spring tuning is needed in this example.
What about the other 40% of the time? Servers also can be tuned. For tomcat there is a lot we can do. For example, like explained in the link, if you find an entry for "SecureRandom" in catalina.out most likely your server is spending valuable seconds generating random patterns for use as session id. Using the below setting saves you those seconds as explained in the link:
I saw under 10 seconds savings after using the below in the app web.xml as suggested in the link:
But what about if actually the time that the application would take to load would be few seconds? Will a user differentiate 10 seconds delay originated from a slow database access or backend channel web service request in comparison with a server restart? The answer is: No, the user experiencing a delay does not really care about the nature of it. If we maintain a proper SLA this will be simply "a hiccup".
Even the fastest web services out there would be slow for certain random actions. You will never know if Gmail is taking longer because of a quick server restart for example. As long as you can get what you need a wait of few seconds won't natter.
If the definition of "Done" is "Deployed to production" developers will take more care of deployment performance. Waiting long time for a deployment, means disruption. Business will never approve minutes of downterm. On the other hand if you increase your WIP limits you will slow down, quality will suffer. This bottleneck becomes a great opportunity for improvement as expected. You have reach a Kaisen moment.
There is a need to work on deplopyment performence. Without addressing that important issue you will constantly delay deployments, you will constantly get more tasks piling up, the consequences will be terrible and will only be discovered if you are actually visualizing the value stream. You need to tune your server and your application for it to load faster. A restart should be a synonym of a snap.
In a typical Spring application you will proceed as with any other application. Logs are your friends. Go ahead and turn on debug level. Search for "initialization completed" and confirm how much time this process takes. In production you better use lazy initialization:
<beans ... default-lazy-init="true">This contributes of course to the overall "Server startup". But there is more to do. Check this out.
It should become evident from simple log inspection what is the culprit for a slow server startup. Let us review the below example:

The first clear issue is that ”Initializing Spring root WebApplicationContext” takes 36 seconds which is almost half of the time the whole server takes to startup. The second issue is that “Initializing Spring FrameworkServlet” takes 14 seconds which is a moderate 10% of the whole server startup time. Spring tuning is needed in this example.
What about the other 40% of the time? Servers also can be tuned. For tomcat there is a lot we can do. For example, like explained in the link, if you find an entry for "SecureRandom" in catalina.out most likely your server is spending valuable seconds generating random patterns for use as session id. Using the below setting saves you those seconds as explained in the link:
-Djava.security.egd=file:/dev/./urandomI found myself saving ten seconds by adding the attribute and node shown below. The explanation again can be found in the provided link:
...
<web-app ... metadata-complete="true">
<absolute-ordering />
...
Eliminating unnecessary jars demands to list them all first. Note that I am sorting them on purpose just in case we are using one in the app that is already included in the container or if we are using two versions of the same (which is impossible if you are using a plugin to check for suplicated anayway):
find /opt/tomcat/ -name "*.jar"|sed 's#.*/##'|sortThen find which classes are inside the those you are unsure if you need or not. Now you do need the whole path so let us pick as an example jtidy-r938.jar which hibernate includes as dependency. Here are the relevant commands which you will need to adapt according to your machine paths:
find /opt/tomcat/ -name "jtidy*.jar" jar -tvf /opt/tomcat/myapp/ROOT/WEB-INF/lib/jtidy-r8-20060801.jar find /home/dev/workspace/ -name "*.java"|xargs grep "org.w3c.tidy"In my case after saving 9MB worth of jar files I saw no startup time savings for the specific project I picked for this research.
I saw under 10 seconds savings after using the below in the app web.xml as suggested in the link:
<web-app ... metadata-complete="true">
<absolute-ordering />
...
The use of the special attribute startStopThreads in server.xml#Engine should have no effect if you are running only one application however I saved some seconds I believe after I turned it on:
<Engine ... startStopThreads="0">
Friday, May 30, 2014
Apache mod-proxy should allow for a retry policy before sending back the response to the client
Apache mod-proxy should allow for a retry policy before sending back the response to the client. There is a failonstatus setting which by definition:
As it stands our only resource is to create an ErrorDocument and include some logic to automatically retry again while communicating the user that a recovery from the error is coming soon. For example you could redirect to the domain root after five seconds with Meta Refresh: This is a feature needed to make sure users do not get an error message when an application server is restarting and so unavailable (500) or when it is available but at a point where the application has not been loaded (503).
failonstatus - A single or comma-separated list of HTTP status codes. If set this will force the worker into error state when the backend returns any status code in the list. Worker recovery behaves the same as other worker errors. Available with Apache HTTP Server 2.2.17 and later.However as soon as the status code is returned for the first time by the backend the proxy sends it back to the client. This behavior should be configurable with for example SilentOnStatus which works just as FailOnStatus but it prevents feedback to be sent back to the client.
As it stands our only resource is to create an ErrorDocument and include some logic to automatically retry again while communicating the user that a recovery from the error is coming soon. For example you could redirect to the domain root after five seconds with Meta Refresh: This is a feature needed to make sure users do not get an error message when an application server is restarting and so unavailable (500) or when it is available but at a point where the application has not been loaded (503).
Thursday, May 22, 2014
Mod proxy suddenly failing with 500 / 502 errors because of self signed expired certificates
Apache was returning 500. From logs:
The open ssl self certificate validation would say:
So it will not state the classical "Verify return code: 10 (certificate has expired)" when indeed the certificate is expired. That is why you better check for expiration directly:
Thursday, May 15, 2014
Talend Open Source needs Dynamic Schema for Delimited files
Talend Open Source needs Dynamic Schema for Delimited files. Only the commercial version allows dynamic schema.
We need to build a component called tFileInputDelimitedExtract. You could use tFileInputCSVFilter as a reference for the implementation. Unfortunately I don't have the time at the moment for this implementation but at least let me enunciate the specifications for it in case someone decides to go further with the implementation. It could be a good project for someone willing to learn talend component creation for example. At the moment a quick "hack" for new unexpected inner columns would be to use 'cut' to exclude them. Below we remove the 7th unneeded column from a pipe delimited file:
We need to build a component called tFileInputDelimitedExtract. You could use tFileInputCSVFilter as a reference for the implementation. Unfortunately I don't have the time at the moment for this implementation but at least let me enunciate the specifications for it in case someone decides to go further with the implementation. It could be a good project for someone willing to learn talend component creation for example. At the moment a quick "hack" for new unexpected inner columns would be to use 'cut' to exclude them. Below we remove the 7th unneeded column from a pipe delimited file:
Wednesday, May 14, 2014
Where did your Java architecture go?
Where did your Java architecture go?. Classycle might have good answers for you. It is easier to configure than jdepend which was the de facto open source cycle analyzer before and which you might still want to check out.
Here is how to analyze the spring core jar for example. Even though the below uses plain command line, an eclipse and maven plugins are available at the moment so you might want to check those out. Specially you should build ddf files to enforce your architectural layers and make sure the build fails if it is violated.
Here is how to analyze the spring core jar for example. Even though the below uses plain command line, an eclipse and maven plugins are available at the moment so you might want to check those out. Specially you should build ddf files to enforce your architectural layers and make sure the build fails if it is violated.
Subversion anonymous access for just one directory
In the apache configuration file for the "Location" directive use "Satisfy" before "Require". Note that you might have a second "Require" directive below a "LimitExcept", make sure you *also* use the "Satisfy" there, for example:
Friday, May 09, 2014
Is TDD dead?
Is TDD dead? The question drove today the hangout between Kent Beck, Martin Fowler and David Heinemeier Hanssom.
David is challenging the TDD supporters stating that doing TDD feels most of the time unnatural and not enjoyable. While Kent and Martin agree that TDD is not the perfect solution to resolve all problems they argue it has had a tremendous value for many projects they have had in their hands.
Probably Test Driven Development is not a good technique for all projects, however Test Driven Delivery is. I mean you would never come up with "continuous delivery with high quality" if you do not think about how would you test the feature you are about to ship up front.
Have you ever wondered why so many development teams state exactly the same "Business does not know what they want"? Probably if Business would think about how to test their idea once it is implemented they would not ask for unnecessary features and forget about important ones.
Have you ever wondered why the defect ratio is making impossible for the team to deliver a feature in less than a week? Perhaps if not only user stories but a clear acceptance test criteria (and test cases derived from it) would have been provided the developer would have been automated them because of course the developer is lazy and will not spend time testing manually in two, three or four different environments.
I would say Test Driven Delivery is very much alive. Is the enforcement of Test Driven Development not good?, probably yes if it is an imposition and not a necessity. Velocity and enjoyment cannot be increased at the expense of business value creation.
"In what ways can a desire to TDD damage an architecture?" is the question Martin proposed to be answered. Show us the numbers for a conclusive answer.
There is definitely a way to go from few features delivered once a month to increasingly delivering new features at a quicker pace to achieve multiple daily deployments. That cannot be achieved without the confidence Kent is advocating for.
Make sure issues are required to come with test cases up front, ideas are required to come with acceptance criteria up front and make sure the tests run before the feature is considered delivered.
If Business complains about too much time being spent on testing then keep a backlog of all the acceptance criteria test cases that can be manually followed but were not yet automated, measure the defect ratio AND the cycle time to deliver features (not bug resolutions). Switch back to providing the tests and measure again. The numbers should show that over a period of 3 months the team is able to deliver more features when providing test automation. But ultimately it will demonstrate that having test procedures documented is the very first step to deliver beautiful software that just work as intended, with no more and no less than what is actually required to make money. IMO Quality is the most important non functional requirement.
David is challenging the TDD supporters stating that doing TDD feels most of the time unnatural and not enjoyable. While Kent and Martin agree that TDD is not the perfect solution to resolve all problems they argue it has had a tremendous value for many projects they have had in their hands.
Probably Test Driven Development is not a good technique for all projects, however Test Driven Delivery is. I mean you would never come up with "continuous delivery with high quality" if you do not think about how would you test the feature you are about to ship up front.
Have you ever wondered why so many development teams state exactly the same "Business does not know what they want"? Probably if Business would think about how to test their idea once it is implemented they would not ask for unnecessary features and forget about important ones.
Have you ever wondered why the defect ratio is making impossible for the team to deliver a feature in less than a week? Perhaps if not only user stories but a clear acceptance test criteria (and test cases derived from it) would have been provided the developer would have been automated them because of course the developer is lazy and will not spend time testing manually in two, three or four different environments.
I would say Test Driven Delivery is very much alive. Is the enforcement of Test Driven Development not good?, probably yes if it is an imposition and not a necessity. Velocity and enjoyment cannot be increased at the expense of business value creation.
"In what ways can a desire to TDD damage an architecture?" is the question Martin proposed to be answered. Show us the numbers for a conclusive answer.
There is definitely a way to go from few features delivered once a month to increasingly delivering new features at a quicker pace to achieve multiple daily deployments. That cannot be achieved without the confidence Kent is advocating for.
Make sure issues are required to come with test cases up front, ideas are required to come with acceptance criteria up front and make sure the tests run before the feature is considered delivered.
If Business complains about too much time being spent on testing then keep a backlog of all the acceptance criteria test cases that can be manually followed but were not yet automated, measure the defect ratio AND the cycle time to deliver features (not bug resolutions). Switch back to providing the tests and measure again. The numbers should show that over a period of 3 months the team is able to deliver more features when providing test automation. But ultimately it will demonstrate that having test procedures documented is the very first step to deliver beautiful software that just work as intended, with no more and no less than what is actually required to make money. IMO Quality is the most important non functional requirement.
Thursday, May 08, 2014
NFS extremely slow in VMWare Solaris guest
I had to investigate an issue related to slow NFS writes from a VMWare Solaris VM.
To debug protocols issues you need to use of course TCP packet sniffers. So I started with the following test for Solaris: Basically we create a 5MB file and transfer it via NFS. The file was taking two minutes to be transferred. The result from /tmp/capture uncovered a lot of DUP ACKs: From a Linux box we then run something similar: And then I confirmed it the write went fast and with no DUP ACK. After we shipped the issue to Infrastructure they found out the culprint to be the usage of a conflictive network adapter in VMWare. Using vmxnet3 network adapter looks to be the right option when it comes to supporting NFS traffic. No DUP ACK anymore.
To debug protocols issues you need to use of course TCP packet sniffers. So I started with the following test for Solaris: Basically we create a 5MB file and transfer it via NFS. The file was taking two minutes to be transferred. The result from /tmp/capture uncovered a lot of DUP ACKs: From a Linux box we then run something similar: And then I confirmed it the write went fast and with no DUP ACK. After we shipped the issue to Infrastructure they found out the culprint to be the usage of a conflictive network adapter in VMWare. Using vmxnet3 network adapter looks to be the right option when it comes to supporting NFS traffic. No DUP ACK anymore.
Who should define Usability? Ask your users
Who should define Usability? Ask your users. They know better than anybody else.
Even when you have an argument about a backend implementation to deliver a feature try to think about the final impact it will have in UI and UX and then simply ask your users if in doubt, their responses will drive you to come up with the best and simpler approach. Always know *why* you are doing what you are doing.
Even when you have an argument about a backend implementation to deliver a feature try to think about the final impact it will have in UI and UX and then simply ask your users if in doubt, their responses will drive you to come up with the best and simpler approach. Always know *why* you are doing what you are doing.
Administrators should not be able to login from the wild for security reasons
Administrators should not be able to login from the wild for security reasons. This is something Unix and later Linux got right up front. If you want to become a super user or administrator you need to do so after you have gained access to the target system. You still see people doing all kind of stuff to overcome this "limitation". Don't do it!
Nowadays everything needs to be accessible from everywhere, JSON services feed Web Applications and native mobile applications. The trend will continue with the Internet Of Things (IoT), wearables, you name it. But we cannot forget about the basics: An application administrator should not have access to the application from the wild. In fact several other roles should better be restricted to have access to the application only from internal networks. Exposing too much power publicly (even if strong authentication and authorization mechanisms are used) is a vulnerability that we can avoid if we are willing to sacrifice usability for privileged accounts.
The Administrator does not need the same level of usability as the rest of the users. Higher privileged accounts might not need them either. Be wise about IP authorization.
Nowadays everything needs to be accessible from everywhere, JSON services feed Web Applications and native mobile applications. The trend will continue with the Internet Of Things (IoT), wearables, you name it. But we cannot forget about the basics: An application administrator should not have access to the application from the wild. In fact several other roles should better be restricted to have access to the application only from internal networks. Exposing too much power publicly (even if strong authentication and authorization mechanisms are used) is a vulnerability that we can avoid if we are willing to sacrifice usability for privileged accounts.
The Administrator does not need the same level of usability as the rest of the users. Higher privileged accounts might not need them either. Be wise about IP authorization.
Disclosure of ID data or Predictable ID format vulnerabilities
Disclosure of ID data or Predictable ID format vulnerabilities are considered low risk. In fact you can search around and you will find not much about it. For example most folks will highlight the advantages of using UUID versus numbered IDs when it comes to load balancing but few will acknowledge the security issue behind the usage of predictable numbers.
Don't be misled by risk classifications, these vulnerabilities can be serious and could cost companies their mere existence.
I hear statements like "well, if the account is compromised then there is nothing we can do". Actually there is a lot we can do to protect the application against stolen authentication. Double factor authentication is one of them which many times is associated to just the authentication phase but which can be used also as added authorization protection. Sometimes it is just about compromises with usability.
Disclosure of ID data is about listing views. A list should never provide sensitive information. If you want to access such thing you should go an extra step and select first the entity to see that information in the details page only. However there is little protection on doing that. The IDs are still in the list view and from those each detail view can be retrieved. Avoiding listing pages that lead to sensitive information sounds like the only possible defense but still a difficult one to sell. IMO listing pages should exist only for those knowing what they are retrieving, for example records should be originated only when providing keywords like names, addresses, known identifiers, etc.
Predictable ID format is about detail and form views. These types of views will demand the use of an ID. If that ID is predictable like an incremental number then someone can easily pull the sensitive data for all IDs. If your current model uses sequential, general numeric IDs or even symmetric encrypted IDs you should consider using a map from those to a random stored value. You could achieve this if you generate a random UUID per real ID and store it in a mapping table. You can then expose to the user just the UUID while still persisting the real ID.
Defense is to be practiced in depth. Even if the account is compromised you can still avoid a list of sensible information across your client base to be accessible from the wild.
Don't be misled by risk classifications, these vulnerabilities can be serious and could cost companies their mere existence.
I hear statements like "well, if the account is compromised then there is nothing we can do". Actually there is a lot we can do to protect the application against stolen authentication. Double factor authentication is one of them which many times is associated to just the authentication phase but which can be used also as added authorization protection. Sometimes it is just about compromises with usability.
Disclosure of ID data is about listing views. A list should never provide sensitive information. If you want to access such thing you should go an extra step and select first the entity to see that information in the details page only. However there is little protection on doing that. The IDs are still in the list view and from those each detail view can be retrieved. Avoiding listing pages that lead to sensitive information sounds like the only possible defense but still a difficult one to sell. IMO listing pages should exist only for those knowing what they are retrieving, for example records should be originated only when providing keywords like names, addresses, known identifiers, etc.
Predictable ID format is about detail and form views. These types of views will demand the use of an ID. If that ID is predictable like an incremental number then someone can easily pull the sensitive data for all IDs. If your current model uses sequential, general numeric IDs or even symmetric encrypted IDs you should consider using a map from those to a random stored value. You could achieve this if you generate a random UUID per real ID and store it in a mapping table. You can then expose to the user just the UUID while still persisting the real ID.
Defense is to be practiced in depth. Even if the account is compromised you can still avoid a list of sensible information across your client base to be accessible from the wild.
Monday, May 05, 2014
Solaris killall command kills all active processes rather that killing all processes by name
Solaris killall command kills all active processes rather that killing all processes by name. This is confusing for those more used to Linux as the command killall in Solaris as per man pages "kill all active processes" but in Linux you read "kill processes by name". Use something like the below in Solaris:
On Defense in Depth: Web Application Security starts at checking the source IP
On Defense in Depth: Web Application Security starts at checking the source IP. Even if you have firewalls and proxies in front of your application server you must have access as a developer to the original IP for the user and the URLs managing private information must be restricted to Intranet use.
Let us say for example that you have prepared a report with a list of users with some sensitive information (like their real home addresses) for certain high privileged roles only. Let us supposed this has ben exposed not only in your intranet web front end but also on the one facing the outside. Right there your issues start. Now, the user can access this information from outside the company premises which means it will be of public knowledge if the user session is compromised.
However if you have designed your middle tier to check for the source IP the user won't be able to access the service from outside even if the functionality leaked for whatever reason.
It is then crucial that all sensitive information related HTTP endpoints are identified. Those should not allow external IPs. It is also crucial to inspect your logs and confirm that you are getting the real IPs from the users that are hitting your system.
Use Defense in Depth concepts when building applications.
Let us say for example that you have prepared a report with a list of users with some sensitive information (like their real home addresses) for certain high privileged roles only. Let us supposed this has ben exposed not only in your intranet web front end but also on the one facing the outside. Right there your issues start. Now, the user can access this information from outside the company premises which means it will be of public knowledge if the user session is compromised.
However if you have designed your middle tier to check for the source IP the user won't be able to access the service from outside even if the functionality leaked for whatever reason.
It is then crucial that all sensitive information related HTTP endpoints are identified. Those should not allow external IPs. It is also crucial to inspect your logs and confirm that you are getting the real IPs from the users that are hitting your system.
Use Defense in Depth concepts when building applications.
Sunday, May 04, 2014
Friday, May 02, 2014
Recreating accidentally deleted vfstab in Solaris
So you have accidentally deleted vfstab in Solaris? You should look into /etc/mnttab:
You can recreate /etc/vfstab out of it but you will need some understanding of the different fields. Or you can always look at a similar machine for guidance. For the above in /etc/vfstab we will end up with:
Just run 'mount -a' to verify everything will mount correctly. Good luck!
Thursday, May 01, 2014
Use PDF Bash Tools when your BI tooling like Talend is not enough
Use PDF Bash Tools for quick pdf manipulation from command line. Ghostscript and xpdf, both open source are a great combination to get the most difficult PDF transformations done.
If your BI Framework / Tooling does not have good solutions for processing pdf files ( like it is the case of Talend ) then you can leverage your old friend, the shell and in specific bash. Simple and effective.
If your BI Framework / Tooling does not have good solutions for processing pdf files ( like it is the case of Talend ) then you can leverage your old friend, the shell and in specific bash. Simple and effective.
Wednesday, April 30, 2014
Small and Medium tests should never fail in Continuous Integration ( CI )
Small and Medium tests should never fail in Continuous Integration ( CI ). If they fail then the developer is not testing locally before a commit to the share version control system.
Large tests are two expensive and most likely you will need a cluster for them to run in a reasonable amount of time. This is better addressed then in a shared environment.
If small and medium tests are run locally why do we need them to run again in CI? That is a very good question. Are we really applying DRY?
Large tests are two expensive and most likely you will need a cluster for them to run in a reasonable amount of time. This is better addressed then in a shared environment.
If small and medium tests are run locally why do we need them to run again in CI? That is a very good question. Are we really applying DRY?
Continuous integration ( CI ) makes technology debt irrelevant
Continuous integration ( CI ) makes technology debt irrelevant. Technology bugs are addressed right away to make the CI pipeline happy. There is no need for business consent to open an application bug, nor prioritization related cost, nor user base penalties because of instability.
I would go further and challenge: Why refactoring needs a special tech debt issue tracking number? The team has a velocity / throughput and just needs to strive to make it better. The team knows better what technology debt needs to be addressed with urgency when a ticket related to the code in need pops up. There is no better way to make the team member aware than a marker in the code (TODO ?).
This shift from a ticketing system back to code annotations will allow the team to understand that "nice to have" are equivalent of YAGNI and should be discarded, it will eliminate operational cost around organizing issues that only the team really understand and for which business operations and analysts have nothing to really say. Ultimately this will allow the team to deliver the Minimum Marketable Feature (MMF) with the best possible quality at the fastest possible rate.
I would go further and challenge: Why refactoring needs a special tech debt issue tracking number? The team has a velocity / throughput and just needs to strive to make it better. The team knows better what technology debt needs to be addressed with urgency when a ticket related to the code in need pops up. There is no better way to make the team member aware than a marker in the code (TODO ?).
This shift from a ticketing system back to code annotations will allow the team to understand that "nice to have" are equivalent of YAGNI and should be discarded, it will eliminate operational cost around organizing issues that only the team really understand and for which business operations and analysts have nothing to really say. Ultimately this will allow the team to deliver the Minimum Marketable Feature (MMF) with the best possible quality at the fastest possible rate.
Monday, April 28, 2014
List canonical hexadecimal ascii contents of a file
To list canonical hexadecimal + ascii contents of a file use hexdump command:
Sunday, April 27, 2014
API usability is not different than application usability
API usability is not different than application usability. A good application must be designed for the best possible user experience. An Application Programming Interface must be as well.
So next time you are creating that interface to expose to a consumer regardless if that will be the lead of your country or a software developer work *with* your consumer(s) to make sure you get it right.
Separation Of Concerns (SoC) helps on that. Even if you have an all star team where everybody does from A to Z in the SDLC you might end up with greatest results if you divide the work and rotate the team through the different concerns. You will naturally avoid violation of SoC.
So next time you are creating that interface to expose to a consumer regardless if that will be the lead of your country or a software developer work *with* your consumer(s) to make sure you get it right.
Separation Of Concerns (SoC) helps on that. Even if you have an all star team where everybody does from A to Z in the SDLC you might end up with greatest results if you divide the work and rotate the team through the different concerns. You will naturally avoid violation of SoC.
Saturday, April 26, 2014
Diversity in the team? Psychology is important
Diversity in the team? Psychology is important for everyone.
Certainly sa the saying goes "when in Rome, do as the Romans do" is an important aspect for the individuals. Bit how about a group of diverse individuals working as part of a team?
While the saying still goes, can't ignore the bit of tolerance you will need to cope with differences. Going more diverse brings strengths for the company but without the right team psychology diversity can result in a double edge sword. Start from making sure the mission, vision and strategy is well understood and accept the fact that everybody is different so know what to expect from each member encouraging everybody to care about the common goal and put aside the differences.
Certainly sa the saying goes "when in Rome, do as the Romans do" is an important aspect for the individuals. Bit how about a group of diverse individuals working as part of a team?
While the saying still goes, can't ignore the bit of tolerance you will need to cope with differences. Going more diverse brings strengths for the company but without the right team psychology diversity can result in a double edge sword. Start from making sure the mission, vision and strategy is well understood and accept the fact that everybody is different so know what to expect from each member encouraging everybody to care about the common goal and put aside the differences.
Agile Interdependence: As a software engineer I want to read the founding fathers so that I know my rights and duties
What is agile interdependence? As a software engineer I want to read the founding fathers so that I know my rights. You are excited about a lot of languages and technologies but without the social guidance you will not easily fit as part of a team.
My recommendation: Read and make IT and non IT departments read three important documents:
My recommendation: Read and make IT and non IT departments read three important documents:
Have a product vision before blaming the IT mission statement
I think a perfect mission statement for a software development team is "High Quality for predictable delivery".
And without a doubt I believe that with that mindset in place if a team is still not bringing value to the company then the product vision is wrong.
And without a doubt I believe that with that mindset in place if a team is still not bringing value to the company then the product vision is wrong.
Non Functional Requirements should be sticky: Quality, Usability, Performance and Capacity
Non Functional Requirements should be sticky. I argue that Quality, Usability, Performance and Capacity are the three you must keep an eye on as a priority. These define the success of any product including software applications.
The application must be tested. The tests have to be automated because otherwise the quality cannot be guaranteed over time as the amount of features to be tested goes up. Dr. William Edwards Deming philosophy for quality control can be summarized in the below ratio which should be interpreted as: Quality increases when the ratio as a whole is higher, not when the focus is just in eliminating cost. If you focus just on cutting cost most likely you are pushing problems for a near future when rework will be needed in order to correctly fix your product. The application must be user friendly, it must do what the user expects with the minimum user effort. Any extra mouse action, voice command, keyboard hit does matter. Usability matters.
The application is supposed to wait for the user, not the other way around. Performance matters.
The application must handle the expected load. How many users are expected to hit the new feature? Will the traffic be spontaneous because of a mailing campaign? Do not assume your system will handle any load. Do your math and avoid surprises. Capacity matters.
The application must be tested. The tests have to be automated because otherwise the quality cannot be guaranteed over time as the amount of features to be tested goes up. Dr. William Edwards Deming philosophy for quality control can be summarized in the below ratio which should be interpreted as: Quality increases when the ratio as a whole is higher, not when the focus is just in eliminating cost. If you focus just on cutting cost most likely you are pushing problems for a near future when rework will be needed in order to correctly fix your product. The application must be user friendly, it must do what the user expects with the minimum user effort. Any extra mouse action, voice command, keyboard hit does matter. Usability matters.
The application is supposed to wait for the user, not the other way around. Performance matters.
The application must handle the expected load. How many users are expected to hit the new feature? Will the traffic be spontaneous because of a mailing campaign? Do not assume your system will handle any load. Do your math and avoid surprises. Capacity matters.
Wednesday, April 23, 2014
On Agile: Minimum Marketable Feature (MMF) is key for the team survival
Minimum Marketable Feature (MMF) is key for the team survival. This is specially true for small software development teams in non software centric companies.
Ask yourself if that issue you are addressing will have a direct impact on a non software developer geek life. If Business ends up stating that the feature results in a high Return On Investment ( ROI ) in a very short period of time then you have created or contributed to a Marketable feature.
Then it comes MMF. The feature that will take you the minimal possible time to develop and still the reaction from Business will be the above.
If the team is not producing enough MMF most likely Business is actively looking at alternatives.
This is not a Manager concern, this is your concern as a team member, no matter what your position is. I rather read a resume that states "I delivered 12 MMF in a year" than "I saved a million dollar in a one year long project". The first statement denotes clearer and longer term strategical thinking.
This is a great question to ask in an interview like I proposed in LinkedIn, specially for those that are closer to C level executives like the case of Project Managers:
What are the top 12 minimal marketable features your team produced during your best year as PM?
Correct answer: Mention at least 12 MMF explaining real tangible value.
Incorrect answer: Not able to mention at a minimum 12 (1 per month) or not able to provide clear explanation of projected or realized ROI for each of them.
Ask yourself if that issue you are addressing will have a direct impact on a non software developer geek life. If Business ends up stating that the feature results in a high Return On Investment ( ROI ) in a very short period of time then you have created or contributed to a Marketable feature.
Then it comes MMF. The feature that will take you the minimal possible time to develop and still the reaction from Business will be the above.
If the team is not producing enough MMF most likely Business is actively looking at alternatives.
This is not a Manager concern, this is your concern as a team member, no matter what your position is. I rather read a resume that states "I delivered 12 MMF in a year" than "I saved a million dollar in a one year long project". The first statement denotes clearer and longer term strategical thinking.
This is a great question to ask in an interview like I proposed in LinkedIn, specially for those that are closer to C level executives like the case of Project Managers:
What are the top 12 minimal marketable features your team produced during your best year as PM?
Correct answer: Mention at least 12 MMF explaining real tangible value.
Incorrect answer: Not able to mention at a minimum 12 (1 per month) or not able to provide clear explanation of projected or realized ROI for each of them.
Subscribe to:
Posts (Atom)

