Sunday, December 31, 2017
Google Cloud Platform Inventory
I just finalized what I believe is the simplest possible way to extract a Google Cloud Platform Inventory (GCP). Unfortunately GCP does not support triggers for functions as Amazon Web Services (AWS) does with Lambdas so we are (at least for now) forced to use cron. Google Customer Support did issue a feature request and hopefully they will deliver at some point a truly serverless scheduler for Cloud Functions. When GCP supports triggers the code should be almost ready as it uses nodejs. BTW working with async/await makes nodejs really attractive for OS related tasks (read DevOps).
Thursday, December 21, 2017
Tail your logs from a web interface - rtail
Let us say you want to see realtime some logs like those coming from your lean release, deploy and e2e pipeline. Here is how to use rtail to expose logs streams on a web interface:
Stream logs via rtail client with simple and effective cron:
At this point http://localhost:8080 should list the available streams and the log traces coming in from them.
WARNING: At the time of this writing there is a stream mixed output bug you should be aware of (https://github.com/kilianc/rtail/issues/110) . To go around it use the below:
-
Expose streams using rtail-server
sudo npm install -g rtail mkdir ~/rtail-server cd ~/rtail-serverCreate a process.yaml in that directory
apps:
- script : rtail-server
name: 'rtail-server'
instances: 0
exec_mode: cluster
merge_logs: true
args: "--web-port 8080 --web-host 0.0.0.0"
Run it
pm2 start process.yaml pm2 save # logs are in ~/.pm2
* * * * * ( flock -n 1 || exit 0; tail -F /var/log/ci/release.log | rtail --id "release.log" ) 1>~/rtail-release.lock * * * * * ( flock -n 2 || exit 0; tail -F /var/log/ci/gke-deploy.log | rtail --id "deploy.log" ) 2>~/rtail-deploy.lock * * * * * ( flock -n 3 || exit 0; tail -F /var/log/ci/e2e.log | rtail --id "e2e.log" ) 3>~/rtail-e2e.lock
sudo cp /usr/local/lib/node_modules/rtail/cli/rtail-server.js /usr/local/lib/node_modules/rtail/cli/rtail-server.js.old
sudo curl https://raw.githubusercontent.com/mfornasa/rtail/ed16d9e54d19c36ff2b76e68092cb3188664719f/cli/rtail-server.js -o /usr/local/lib/node_modules/rtail/cli/rtail-server.js
ps -ef | grep rtail-server | grep -v grep | awk '{print $2}' | xargs kill
diff /usr/local/lib/node_modules/rtail/cli/rtail-server.js /usr/local/lib/node_modules/rtail/cli/rtail-server.js.old
Just refresh your browser and wait till the streams show up again.
Thursday, December 14, 2017
Close your SpiceWorks account
Incredibly difficult to get to it, no link anywhere. I had to dig into very old posts until actually I run into https://community.spiceworks.com/profile/close_account. After closing I was redirected to https://community.spiceworks.com/profile/show/ but such resource is broken:
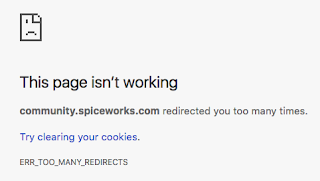
If you have other accounts to close you will need to kill your cookies for the domain because you will be redirected otherwise to the above page.
The good news is that it worked.

If you have other accounts to close you will need to kill your cookies for the domain because you will be redirected otherwise to the above page.
The good news is that it worked.
Saturday, December 09, 2017
Migrating Spiceworks to JIRA Service Desk
Let's keep this simple. I will consider a Spiceworks installation that defaults to sqlite3. It is amazing how much this can handle BTW. It gets slow but man, I saw recently over 1GB of sqlite data handled by a SpiceWorks installation. Well, I did know sqlite rocks and not just in mobile devices.
- Install sqlite3 (command line) in the Spiceworks server
- Copy the db (for example from C:\Program Files (x86)\Spiceworks\db) to the sqlite bin directory
- Access the db from sqlite
sqlite3 spiceworks-prod.db
- From sqlite prompt export relevant fields:
.headers on .mode csv .output spiceworks-prod.csv select tickets.id as ticket_id, tickets.created_at, tickets.summary, tickets.description, (select email from users where users.id = tickets.assigned_to) as assigned_to, tickets.category, tickets.closed_at, (select email from users where users.id = tickets.created_by) as created_by, tickets.due_at, tickets.status, tickets.updated_at, tickets.summary, group_concat(comments.created_at || " - " || (select email from users where users.id = comments.created_by) || " - " || comments.body, " [COMMENT_END] ") as comment from tickets, comments where comments.ticket_id=tickets.id group by ticket_id order by comments.ticket_id,comments.id;
- Use JIRA CSV File Import, point to generated file spiceworks-prod.csv, select file encoding UTF-8, date format yyyy-MM-dd HH:mm:ss, leave imported users inactive, map status field (closed to Done; open to Open)
- When done importing, save configuration and the import logs
- Optional: If you are into lean thinking you might want to read a bit about classes of service and triage systems or just trust me that this is the simplest way to prioritize your work. To that end go to JIRA Service Desk settings / issues / priorities and use them as class of service. You will need to keep only three and change their name (Mark standard as default):
- Expedite: There is no workaround. There is a tangible impact to the business bottom line.
- Fixed Delivery Date: There is no workaround. It must be done before certain date. It impacts the business bottom line
- Standard: First In First Out. There is a workaround. It impacts the business bottom line.
Friday, December 08, 2017
Correctly generate CSV that Excel can automatically open
Software generating CSV should include the byte order mark (BOM) at the start of the text stream. If this byte is missing programs like Excel won't know the encoding and functionality like just double clicking the file to open it with Microsoft Excel won't work as expected in Windows neither MAC.
You might want to do a simple test yourself. Let us say that you have a BOM missing UTF-8 CSV and when opened in Excel it renders garbled text. If you open such file in Notepad and save it back with a different name, selecting UTF-8, the new file will be rendered correctly. If you compare the two files (using a nix system) you will notice the difference is in three bytes that specify the encoding of the CSV:
You might want to do a simple test yourself. Let us say that you have a BOM missing UTF-8 CSV and when opened in Excel it renders garbled text. If you open such file in Notepad and save it back with a different name, selecting UTF-8, the new file will be rendered correctly. If you compare the two files (using a nix system) you will notice the difference is in three bytes that specify the encoding of the CSV:
$ diff <(xxd -c1 -p original.csv <(xxd -c1 -p saved-as-utf8.csv) 0a1,3 > ef > bb > bfTell the software developer in charge of generating the CSV to correct it. As a quick workaround you can use gsed to insert the UTF-8 BOM at the beginning of the string:
gsed -i '1s/^\(\xef\xbb\xbf\)\?/\xef\xbb\xbf/' file.csvThis command inserts the UTF-8 BOM if not present. Therefore it is an idempotent command.
Saturday, December 02, 2017
JIRA revoke license to multiple users from the user interface
I needed to revoke application access to 400 old users that were imported from a different issue management system via CSV import. To my surprise the current JIRA cloud version expect us to click one user at a time when revoking licenses. Javascript to the rescue: Right click the page in chrome, select inspect, click console, paste the below and hit enter. It will click the revoke button every 3 seconds (adjust time depending on your needs):
var interval = setInterval(function() { document.getElementsByClassName('revoke-access')[1].click() }, 3000);
When done, run the below to stop the loop:
clearInterval(interval);
Wednesday, November 08, 2017
Google Cloud Support Center URL - Manage Cases
I don't know you but for me finding this URL link requires 5 minutes every time I need to report a new case or look at a previous resolved case:
https://enterprise.google.com/supportcenter/managecases
https://enterprise.google.com/supportcenter/managecases
Monday, November 06, 2017
Saturday, October 21, 2017
Simple and precise problem definition leads to the best software specifications
Be simple and precise. Simplicity brings efficiency and preciseness brings effectiveness. They both, combined, bring productivity.
Simple means "easily understood or done; presenting no difficulty". Precise means "clearly expressed or delineated".
See the below simple specification:
The devil is in the details and we cannot be simpler than what is absolutely needed. We kept as much simplicity as we could by structuring our specification using verbs to command what we should do (Create, Update, Assign, Assert) and at the same time we brought preciseness to the mix, specially by using the 'because' keyword for assertions. With simplicity we achieve efficiency and with preciseness we achieve effectiveness. They both, combined, bring productivity.
We resolve the whole problem using cause and effect led specifications: We have actions; an assertion on those *specific* actions and the cause/effect explanation via a 'because' statement. Not only the business rules are clear, but the test case is straightforward and in fact the test case is what drives the whole specification and implementation. It results in a total quality control based software development lifecycle system.
In this post I have explained how the documentation problem can be resolved in a simple and precise manner. I should probably write about how to resolve the QA and implementation problems in a simple and precise manner soon ...
Simple means "easily understood or done; presenting no difficulty". Precise means "clearly expressed or delineated".
See the below simple specification:
"Examine any workflow task with status 'not started' and send a 'tasks pending to be performed' notification to its owner if for such task workflow there is no previous task or if the previous task is in status 'completed'"It is easy to understand and there should be no difficulty involved in its implementation. However this specification is not precise, and because of it the transaction costs will make its implementation at least an order of magnitude more expensive than its counterpart simple and precise specification:
Create task owner 1 Create task owner 2 Create workflow 1 accepting default values Create workflow 2 accepting default values Assert these tasks persist and their status is 'Not Started' because this is the default status and the owner is not a mandatory field Assign owner 1 to workflow 1 task 1 Assign owner 2 to workflow 1 task 2 Assign owner 1 to workflow 2 task 1 Assign owner 2 to workflow 2 task 2 Assert that owner 1 gets two 'tasks pending to be performed' notifications because owner 1 is assigned to the first task of each workflow Assert that owner 2 gets no 'tasks pending to be performed' notifications because owner 2 is assigned to a task with a predecessor task that is not completed yet Update status 'In Progress' for workflow 1 task 1 Update status 'In Progress' for workflow 2 task 1 Assert that no 'tasks pending to be performed' notifications are sent because Owner 1 is still working on his task and Owner 2 should not be working until Owner 1 has finalized her task Update status 'Not Started' for workflow 1 task 1 Update status 'Completed' for workflow 2 task 1 Assert that owner 1 gets one 'tasks pending to be performed' notification for workflow 1 task 1 because this is the first task in the workflow, it is assigned to owner 1 and the task should be started if it is not started Assert that owner 2 gets one 'tasks pending to be performed' notification for workflow 2 task 2 because the previous task was completed and the assigned task has not startedInstead of going through the above top-down exercise that would allow to put automated end to end (e2e) testing in place and guarantee that important business rules are never broken we go lazy both with specs and QA. Documentation and QA are as important as implementing the functionality for your product. The three of them (documentation, implementation, and QA) should be simple and precise.
The devil is in the details and we cannot be simpler than what is absolutely needed. We kept as much simplicity as we could by structuring our specification using verbs to command what we should do (Create, Update, Assign, Assert) and at the same time we brought preciseness to the mix, specially by using the 'because' keyword for assertions. With simplicity we achieve efficiency and with preciseness we achieve effectiveness. They both, combined, bring productivity.
We resolve the whole problem using cause and effect led specifications: We have actions; an assertion on those *specific* actions and the cause/effect explanation via a 'because' statement. Not only the business rules are clear, but the test case is straightforward and in fact the test case is what drives the whole specification and implementation. It results in a total quality control based software development lifecycle system.
In this post I have explained how the documentation problem can be resolved in a simple and precise manner. I should probably write about how to resolve the QA and implementation problems in a simple and precise manner soon ...
Sunday, October 15, 2017
Tail logs from all Kubernetes pods at once with podlogs.sh
Unfortunately you cannot tail and at the same time use selectors:
$ kubectl logs -l 'role=nodejs' --tail=2 -f error: only one of follow (-f) or selector (-l) is allowed See 'kubectl logs -h' for help and examples.However there are alternatives. Here is a how to tail logs from all Kubernetes pods at once using just one Plain Old Bash (POB) script.
Thursday, October 05, 2017
Wednesday, October 04, 2017
upgrading kubernetes - container pods stuck in state 'unknown'
I deleted an old pod that was sticking in our cluster without explanation and it turned into state 'unknown'. Getting logs from nodejs apps was impossible, in fact 'kubectl exec' hanged ssh sessions. I remember that I saw errors like these (pods reluctant to be deleted) when GKE was expecting a k8s upgrade. So I did and the issue got resolved.
Saturday, September 30, 2017
Saturday, September 16, 2017
Auditing file changes in Linux
Audit the file by adding a watch, tail the audit log, remove the watch and list current watches in case you need to remove others.
sudo auditctl -w /path/to/file -p wa sudo tail -f /var/log/audit/audit.log sudo auditctl -W /path/to/file -p wa sudo auditctl -l
Thursday, August 03, 2017
shortcut to get into a kubernetes pod shell
$ grep -B0 -F3 kbash ~/.bashrc
function kbash() {
kubectl exec -ti $1 bash
}
Usage:
kbash some-pod-name-here
Friday, July 28, 2017
Thursday, June 08, 2017
The network folder specified is currently mapped using a different name and password

This happened to me after a failed attempt to map a path I had no access to with my regular user. Selecting to map it with different credentials kept on complaining with this error message. The solution was to:
- Run 'net use' and if the path is present run 'net /delete \\path\to\resource' and/or 'net /delete $DRIVE_LETTER:'
- Run 'runas /profile /user:$DOMAIN\$USER cmd' for any privileged $USER you have used before. Hopefully is not administrator ;-)
- From the new command prompt pertaining to the privilege user follow the first step
- Try to map the drive again as you would usually do (in my case using the "Connect using different credentials")
tail: inotify cannot be used, reverting to polling: Too many open files
Run 'ps -ef' and look for some processes that might be unusually big in number.
Friday, May 19, 2017
The meaning of VueJS "render: h => h(App)"
What is the meaning of the arrow function defining the 'render' VueJS method?:
import Vue from 'vue'
import App from './App.vue'
new Vue({
el: '#app',
render: h => h(App)
})
From https://vuejs.org/v2/guide/render-function.html
Aliasing createElement to h is a common convention you’ll see in the Vue ecosystem and is actually required for JSX. If h is not available in the scope, your app will throw an error.Therefore here is the equivalent of the previous code:
import Vue from 'vue'
import App from './App.vue'
new Vue({
el: '#app',
render: function(createElement) {
return createElement(App);
}
})
The arrow function meaning is: let 'render' be a function that accepts the createElement() function as argument and that returns createElement(App) where App is a VueJS single-file-component.
Here is a working example showing the equivalent of this arrow function. Below is the complete code as well:
<!DOCTYPE html>
<html>
<body>
<div id="app">
</div>
<script src="https://unpkg.com/vue@2.3.3"></script>
<script type="text/javascript">
new Vue({
el: '#app',
// render is a function defined here as accepting the function h as parameter and returning the h result when evaluated with a single file component or in this case a template (in here two params: the tag and the value)
render: h => h('h1', 'Hello')
// Same but probably easier to understand for most humans who prefer long but straightforward text rather than short but cryptic:
/*render: function(createElement) {
return createElement('h1', 'Hello');
}*/
})
</script>
</body>
</html>
BTW there is a cryptic-er way to use a single file component (the ES6 spread operator):
import Vue from 'vue'
import App from './App.vue'
new Vue({
el: '#app',
...App
})
Sunday, May 14, 2017
kubectl get pods listing pods belonging to a different cluster
Issue: kubectl get pods lists pods belonging to a different cluster
Solution:
Solution:
gcloud container clusters get-credentials your-cluster --zone your-zone --project your-project gcloud config set project your-project
Saturday, May 06, 2017
GCS - Bad credentials for bucket - Check the bucket name and your credentials
Issue:
Give credentials access to the bucket: From the JSON file locate client_email, go to GCP Console / Storage / Browser / Select bucket / Edit Bucket permissions / Add Item / User:$client_email, access:writer
$ gcsfuse --key-file /path/to/credentials.json my-bucket /tmp/my-bucket/ daemonize.Run: readFromProcess: sub-process: mountWithArgs: mountWithConn: setUpBucket: OpenBucket: Bad credentials for bucket "my-bucket". Check the bucket name and your credentials.Solution:
Give credentials access to the bucket: From the JSON file locate client_email, go to GCP Console / Storage / Browser / Select bucket / Edit Bucket permissions / Add Item / User:$client_email, access:writer
Tuesday, May 02, 2017
ERROR: (gcloud...) ResponseError: code=403, message=Required "..." permission for "projects/..."
Issue: I got the below after trying to access Google Container Engine from a MAC:
ERROR: (gcloud.container.clusters.list) ResponseError: code=403, message=Required "container.clusters.list" permission for "projects/myproject".Solution: Run the below to make sure you select the right project (id, not name) and Google account:
gcloud projects list gcloud config set projectgcloud auth login
Friday, April 28, 2017
kubectl get pods - The connection to the server w.x.y.z was refused - did you specify the right host or port
$ kubectl get pods The connection to the serverSolution:was refused - did you specify the right host or port
$ gcloud container clusters get-credentials your-cluster --zone us-east1-b --project your-projectOther issues I have found that get resolved with the same command:
- Unable to connect to the server: x509: certificate signed by unknown authority
- Unable to connect to the server: dial tcp w.x.y.z:443: i/o timeout
Tuesday, March 14, 2017
Unit and End to End (e2e) Testing should be enough - the rest are intangible
I have learned from my years as full time developer that (those tests, that according to Google's classification are called medium), are a life saver. I have also learned from my years as a team leader that these tests are the perfect excuse to deliver tight coupled, AKA 3v1l untestable code.
If Unit tests are covering all the functionality of your loosely couple software and e2e tests are covering all common scenarios followed by your users, I would name the medium tests "intangible tests". They are useful as ad-hoc tests that aim at getting a proof of concept (POC) out of the door. However maintaining them, relying on them for application quality and delaying your delivery because of them will be nothing more than paying a big opportunity cost.
Quick Glossary:
If Unit tests are covering all the functionality of your loosely couple software and e2e tests are covering all common scenarios followed by your users, I would name the medium tests "intangible tests". They are useful as ad-hoc tests that aim at getting a proof of concept (POC) out of the door. However maintaining them, relying on them for application quality and delaying your delivery because of them will be nothing more than paying a big opportunity cost.
Quick Glossary:
- Small Tests: "Local Memory" Tests. Hopefully your current Unit tests.
- Medium Tests: "Local Host" Tests. Hopefully you don't maintain them.
- Large Tests: "Any Host" Tests. Hopefully your current e2e tests.
Tuesday, March 07, 2017

Sunday, February 19, 2017
Sunday, January 22, 2017
Distributed Document Management Systems DDMS on AWS - Disruption!
There are two killer features AWS Elastic File System (EFS) needs to deliver:
This is my official comment to Mount NFSv4.1 with Windows. I had to comment here since my "account is not ready for posting messages yet" and I do not want to "try again later".
- AWS NFS 4.1 Encryption support
- AWS NFS 4.1 Windows Explorer integrated Client or alike
This is my official comment to Mount NFSv4.1 with Windows. I had to comment here since my "account is not ready for posting messages yet" and I do not want to "try again later".
Friday, January 13, 2017
On Security: Is your site still drown - ing?
If you are using the same certificate in several servers and just one of them happens to have SSLv2 enabled then all of your servers are vulnerable to the DROWN attack. Do not be misled by results from tools like nmap or sslyze. Better to not have shared keys and make sure of course SSLv2 is not allowed in any of your servers.
Thursday, January 05, 2017
Monitoring Linux Resources in AWS and beyond with Plain Old Bash ( POB )
As I already posted Amazon Web Services (AWS) is not providing an out of the box solution for such simple thing as monitoring HDD, Memory and CPU usage for Windows. The situation is the same for Linux. That is the reason I went ahead and created a quick plain old bash (POB) script for this matter. I recommend reading the README.md for straight and quick instructions to get it working in less than a minute. The code is in github but for convenience find the linked content below:
Wednesday, January 04, 2017
Monitoring Windows Resources in AWS and beyond with PowerShell
Amazon Web Services (AWS) is not providing an out of the box solution for such simple thing as monitoring HDD, Memory and CPU usage. CloudWatch demands still some coding and customization for something that IMO should be provided out of the box. We have Monit for Linux but nothing simple enough for Windows. Prometheus is great but probably overkilling for a small startup. That is the reason I went ahead and created a quick PowerShell script for this matter:
Tuesday, January 03, 2017
Install telnet client in Windows
Heads up, it might take a minute for the command to be available after installing it through the below command:
pkgmgr /iu:"TelnetClient"
Subscribe to:
Comments (Atom)

